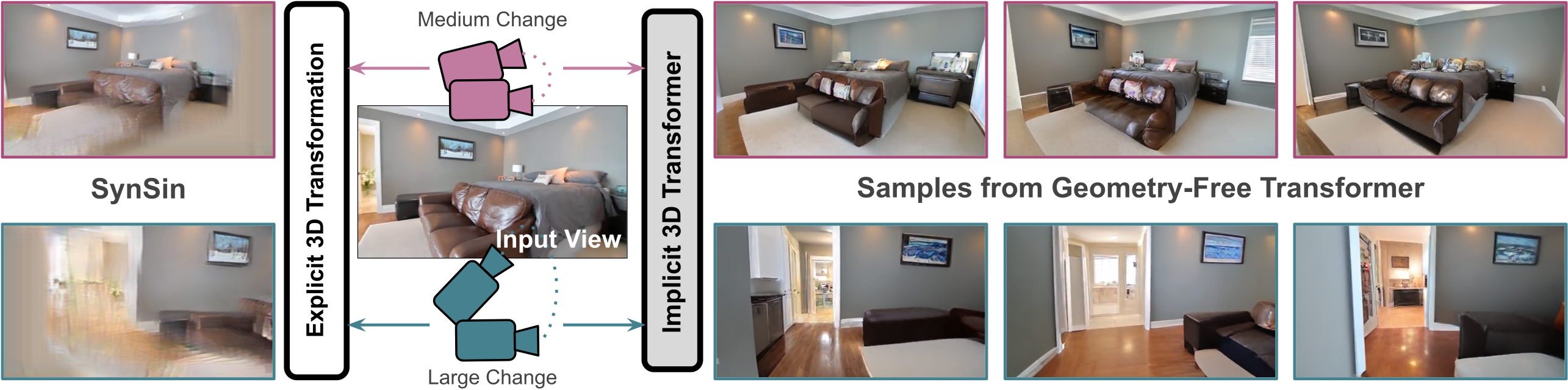
 TL;DR:
We present a probabilistic approach to Novel View
Synthesis based on transformers, which does not
require explicit 3D priors. Given a single source
frame and a camera transformation (center), we
synthesize plausible novel views that exhibit high
fidelity (right). For comparison,
SynSin (left)
yields uniform surfaces and unrealistic warps for
large camera transformations.
TL;DR:
We present a probabilistic approach to Novel View
Synthesis based on transformers, which does not
require explicit 3D priors. Given a single source
frame and a camera transformation (center), we
synthesize plausible novel views that exhibit high
fidelity (right). For comparison,
SynSin (left)
yields uniform surfaces and unrealistic warps for
large camera transformations.

Abstract
Is a geometric model required to synthesize novel views from a single image? Being bound to local convolutions, CNNs need explicit 3D biases to model geometric transformations. In contrast, we demonstrate that a transformer-based model can synthesize entirely novel views without any hand-engineered 3D biases. This is achieved by (i) a global attention mechanism for implicitly learning long-range 3D correspondences between source and target views, and (ii) a probabilistic formulation necessary to capture the ambiguity inherent in predicting novel views from a single image, thereby overcoming the limitations of previous approaches that are restricted to relatively small viewpoint changes. We evaluate various ways to integrate 3D priors into a transformer architecture. However, our experiments show that no such geometric priors are required and that the transformer is capable of implicitly learning 3D relationships between images. Furthermore, this approach outperforms the state of the art in terms of visual quality while covering the full distribution of possible realizations.
Results
and applications of our model.
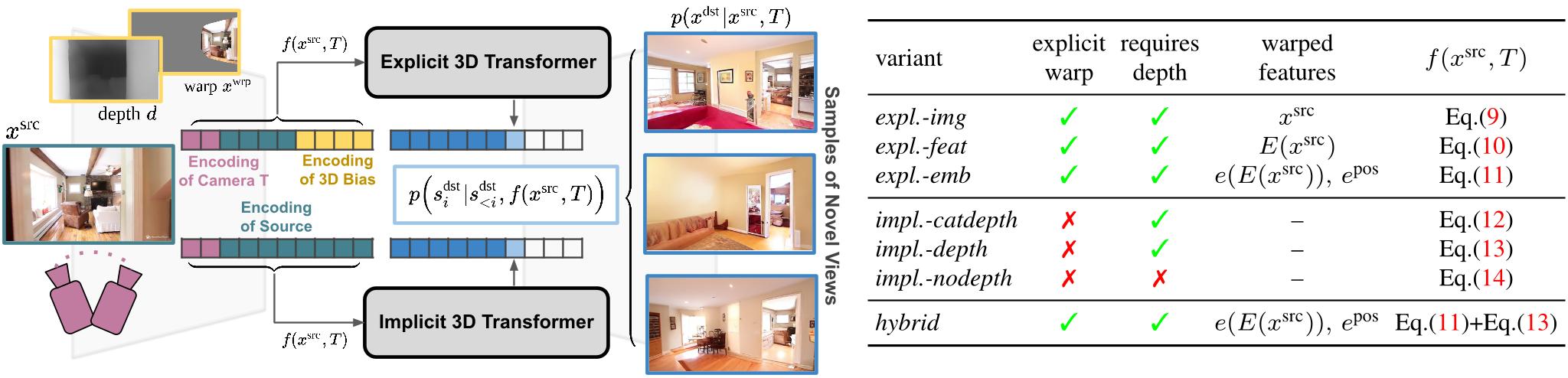 Figure 2. We formulate novel view synthesis as sampling from the distribution p(xdst|xsrc, T ) of target images xdst for a given source image xsrc and camera change T . We use a VQGAN to model this distribution autoregressively with a transformer and introduce a conditioning function f(xsrc, T ) to encode inductive biases into our model. We analyze explicit variants, which estimate scene depth d and warp source features into the novel view, as well as implicit variants without such a warping. The table on the right summarizes the variants for f .
Figure 2. We formulate novel view synthesis as sampling from the distribution p(xdst|xsrc, T ) of target images xdst for a given source image xsrc and camera change T . We use a VQGAN to model this distribution autoregressively with a transformer and introduce a conditioning function f(xsrc, T ) to encode inductive biases into our model. We analyze explicit variants, which estimate scene depth d and warp source features into the novel view, as well as implicit variants without such a warping. The table on the right summarizes the variants for f .
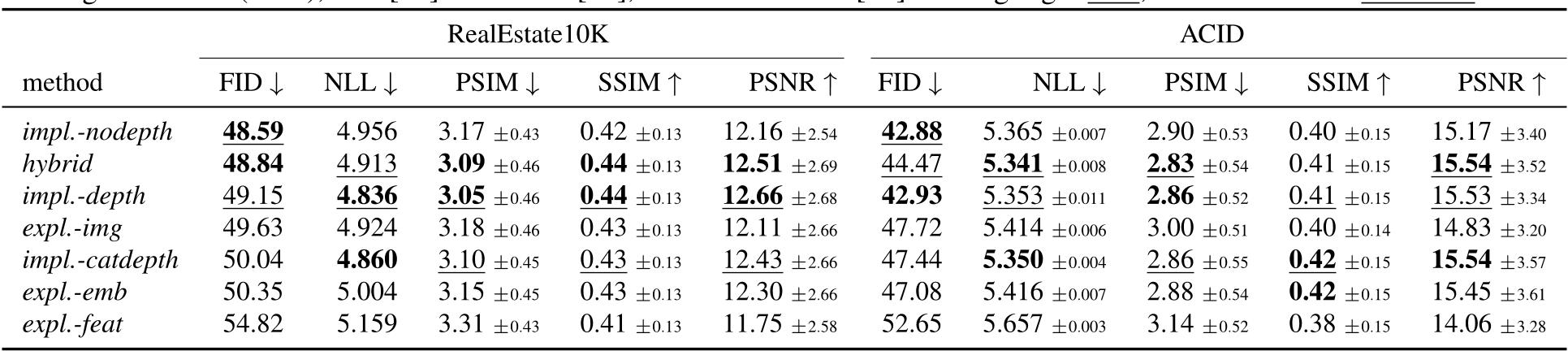 Table 1. To assess the effect of encoding different degrees of 3D prior knowledge, we evaluate all variants on RealEstate and ACID using negative log-likelihood (NLL), FID [28] and PSIM [75], PSNR and SSIM [70]. We highlight best, second best and third best scores.
Table 1. To assess the effect of encoding different degrees of 3D prior knowledge, we evaluate all variants on RealEstate and ACID using negative log-likelihood (NLL), FID [28] and PSIM [75], PSNR and SSIM [70]. We highlight best, second best and third best scores.
 Figure 3. Average reconstruction error of the best sample as a function of the number of samples on RealEstate. With just four samples, impl.-depth reaches state-of-the-art performance in two out of three metrics, and with 16 samples in all three of them.
Figure 3. Average reconstruction error of the best sample as a function of the number of samples on RealEstate. With just four samples, impl.-depth reaches state-of-the-art performance in two out of three metrics, and with 16 samples in all three of them.
 Figure 4. Visualization of the entropy of the predicted target code distribution for impl.-nodepth. Increased confidence (darker colors) in regions which are visible in the source image indicate its ability to relate source and target geometrically, without 3D bias.
Figure 4. Visualization of the entropy of the predicted target code distribution for impl.-nodepth. Increased confidence (darker colors) in regions which are visible in the source image indicate its ability to relate source and target geometrically, without 3D bias.
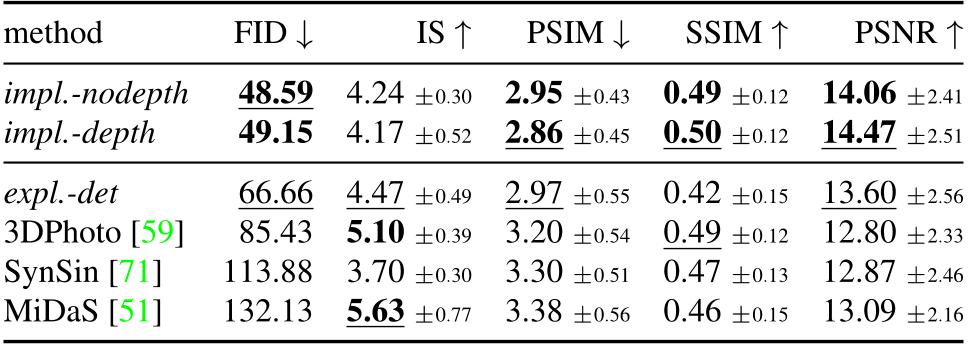 Table 2. Quantitative comparison on RealEstate. Reconstruction metrics are reported with 32 samples, see Fig. 3 for other values. Our implicit variants outperform previous approach in all metrics except for IS, with drastic improvements for FID.
Table 2. Quantitative comparison on RealEstate. Reconstruction metrics are reported with 32 samples, see Fig. 3 for other values. Our implicit variants outperform previous approach in all metrics except for IS, with drastic improvements for FID.
 Figure 5. Qualitative Results on RealEstate10K: We compare three deterministic convolutional baselines (3DPhoto [59], SynSin [71], expl.-det) to our implicit variants impl.-depth and impl.-nodepth. Ours is able to synthesize plausible novel views, whereas others produce artifacts or blurred, uniform areas. The depicted target is only one of many possible realizations; we visualize samples in the supplement.
Figure 5. Qualitative Results on RealEstate10K: We compare three deterministic convolutional baselines (3DPhoto [59], SynSin [71], expl.-det) to our implicit variants impl.-depth and impl.-nodepth. Ours is able to synthesize plausible novel views, whereas others produce artifacts or blurred, uniform areas. The depicted target is only one of many possible realizations; we visualize samples in the supplement.
 Table 3. Quantitative comparison on ACID using 32 samples for reconstruction metrics. We indicate number of steps used for InfNat [37] in parentheses. Our impl.-depth approach outperforms previous works in all metrics except for IS.
Table 3. Quantitative comparison on ACID using 32 samples for reconstruction metrics. We indicate number of steps used for InfNat [37] in parentheses. Our impl.-depth approach outperforms previous works in all metrics except for IS.
 Figure 6. Qualitative Results on ACID: The outdoor setting of the ACID dataset yields similar results as the indoor setting in Fig. 5. Here, we evaluate against the baselines 3DPhoto [59], InfNat [37] and expl.-det. For InfNat [37], we use 5 steps to synthesize a novel view.
Figure 6. Qualitative Results on ACID: The outdoor setting of the ACID dataset yields similar results as the indoor setting in Fig. 5. Here, we evaluate against the baselines 3DPhoto [59], InfNat [37] and expl.-det. For InfNat [37], we use 5 steps to synthesize a novel view.
 Figure 7. Minimal validation loss and reconstruction quality of depth predictions obtained from linear probing as a function of different transformer layers. The probed variant is impl.-nodepth.
Figure 7. Minimal validation loss and reconstruction quality of depth predictions obtained from linear probing as a function of different transformer layers. The probed variant is impl.-nodepth.
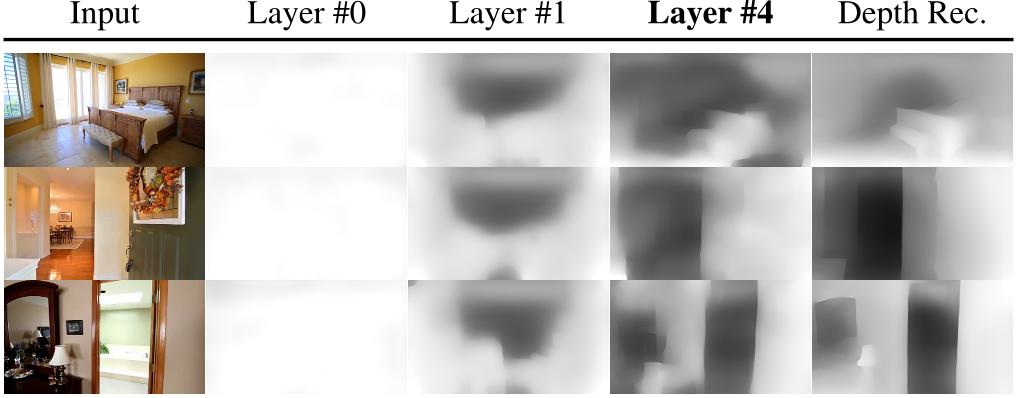 Figure 8. Linearly probed depth maps for different transformer layer. The results mirror the curve in Fig. 7: After a strong initial increase, the quality for layer 4 is best. The depth reconstructions in the right column provide an upper bound on achievable quality.
Figure 8. Linearly probed depth maps for different transformer layer. The results mirror the curve in Fig. 7: After a strong initial increase, the quality for layer 4 is best. The depth reconstructions in the right column provide an upper bound on achievable quality.
 Figure 9. Preview of the videos available at https://git.io/JOnwn, which demonstrate an interface for interactive 3D exploration of images. Starting from a single image, it allows users to freely move around in 3D. See also Sec. A.
Figure 9. Preview of the videos available at https://git.io/JOnwn, which demonstrate an interface for interactive 3D exploration of images. Starting from a single image, it allows users to freely move around in 3D. See also Sec. A.
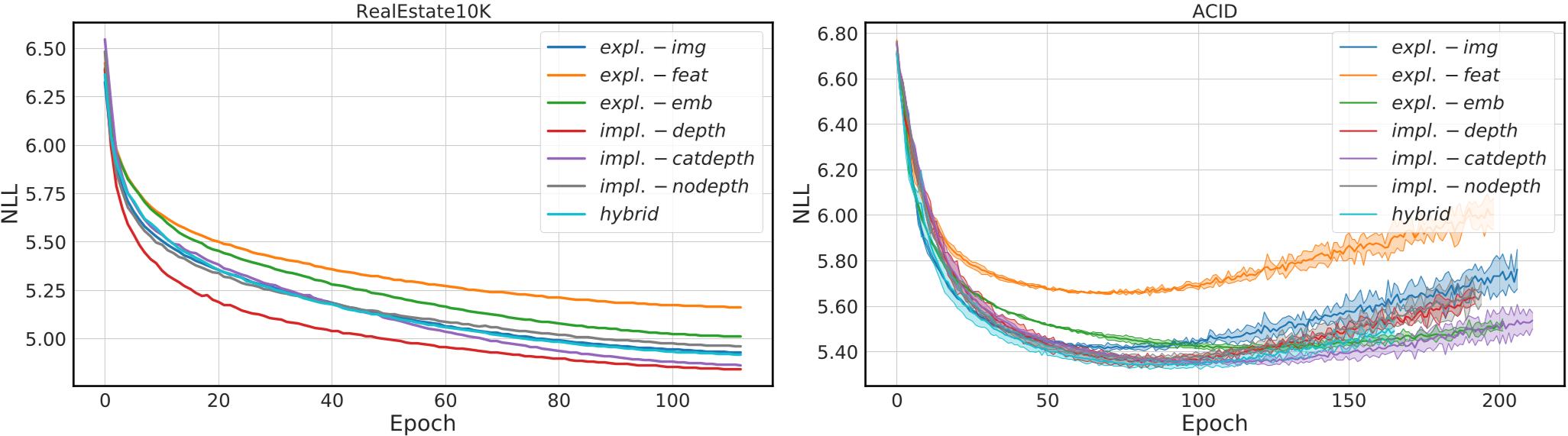 Figure 10. Negative log-likelihood over the course of training on RealEstate10K (left) and ACID (right). Implicit variants achieve the best results, see Sec. 4.1 for a discussion.
Figure 10. Negative log-likelihood over the course of training on RealEstate10K (left) and ACID (right). Implicit variants achieve the best results, see Sec. 4.1 for a discussion.
 Figure 11. Additional qualitative comparisons on RealEstate10K.
Figure 11. Additional qualitative comparisons on RealEstate10K.
 Figure 12. Additional samples on RealEstate10K. The second column depicts the pixel-wise standard deviation σ obtained from n = 32 samples.
Figure 12. Additional samples on RealEstate10K. The second column depicts the pixel-wise standard deviation σ obtained from n = 32 samples.
 Figure 13. Additional qualitative comparisons on ACID.
Figure 13. Additional qualitative comparisons on ACID.
 Figure 14. Additional samples on ACID. The second column depicts the pixel-wise standard deviation σ obtained from n = 32 samples.
Figure 14. Additional samples on ACID. The second column depicts the pixel-wise standard deviation σ obtained from n = 32 samples.
 Figure 15. Additional results on linearly probed depth maps for different transformer layers as in Fig. 8. See Sec. 4.3.
Figure 15. Additional results on linearly probed depth maps for different transformer layers as in Fig. 8. See Sec. 4.3.
 Figure 16. Additional visualizations of the entropy of the predicted target code distribution for impl.-nodepth. Increased confidence (darker colors) in regions which are visible in the source image indicate its ability to relate source and target geometrically, without 3D bias. See also Sec. 4.1 and Sec. D.
Figure 16. Additional visualizations of the entropy of the predicted target code distribution for impl.-nodepth. Increased confidence (darker colors) in regions which are visible in the source image indicate its ability to relate source and target geometrically, without 3D bias. See also Sec. 4.1 and Sec. D.