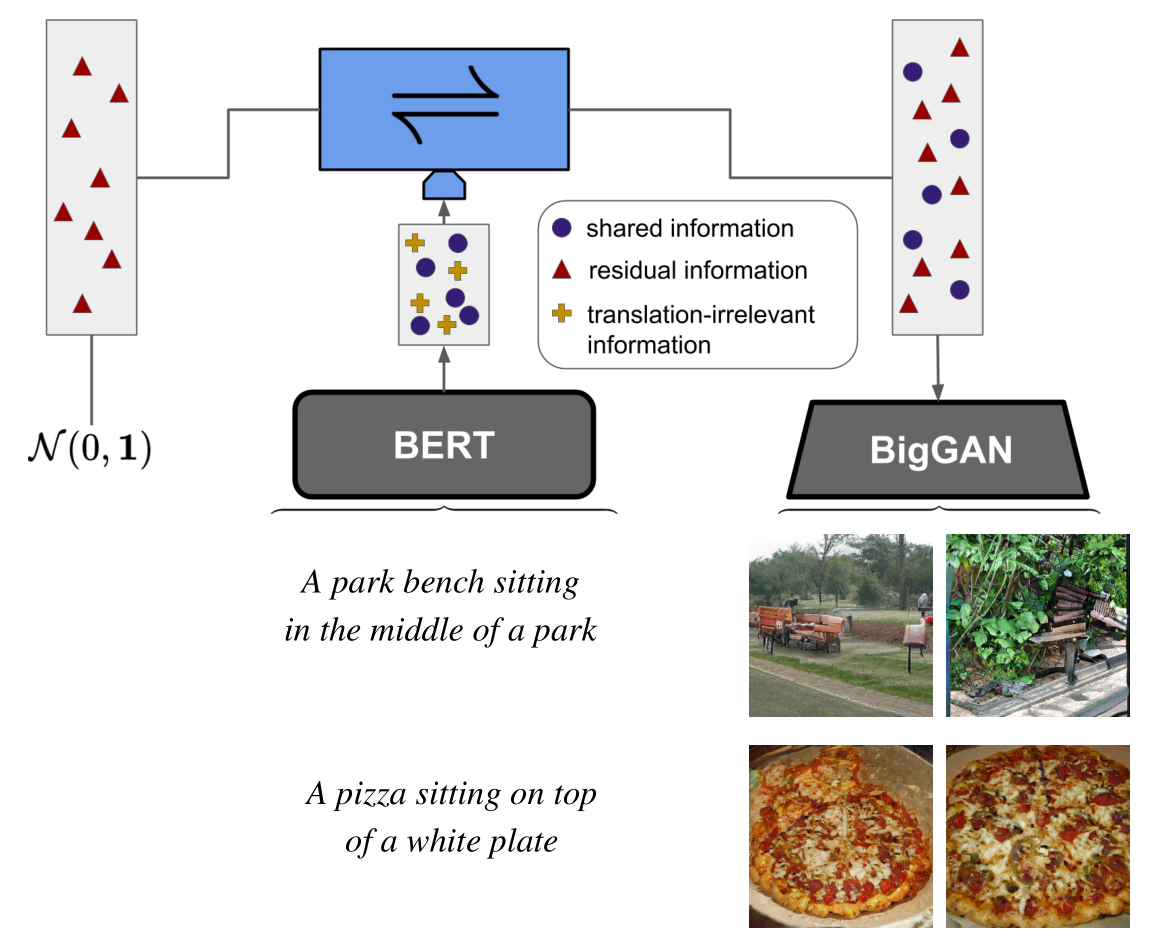
 TL;DR: Our approach distills the residual information of one
model with respect to another's and thereby enables
translation between fixed off-the-shelve expert models
such as BERT and BigGAN without having to modify or
finetune them.
TL;DR: Our approach distills the residual information of one
model with respect to another's and thereby enables
translation between fixed off-the-shelve expert models
such as BERT and BigGAN without having to modify or
finetune them.

Abstract
Given the ever-increasing computational costs of modern machine learning models, we need to find new ways to reuse such expert models and thus tap into the resources that have been invested in their creation. Recent work suggests that the power of these massive models is captured by the representations they learn. Therefore, we seek a model that can relate between different existing representations and propose to solve this task with a conditionally invertible network. This network demonstrates its capability by (i) providing generic transfer between diverse domains, (ii) enabling controlled content synthesis by allowing modification in other domains, and (iii) facilitating diagnosis of existing representations by translating them into interpretable domains such as images. Our domain transfer network can translate between fixed representations without having to learn or finetune them. This allows users to utilize various existing domain-specific expert models from the literature that had been trained with extensive computational resources. Experiments on diverse conditional image synthesis tasks, competitive image modification results and experiments on image-to-image and text-to-image generation demonstrate the generic applicability of our approach. For example, we translate between BERT and BigGAN, state-of-the-art text and image models to provide text-to-image generation, which neither of both experts can perform on their own.
Related Work on Understanding and Disentangling Latent Representations with INNs
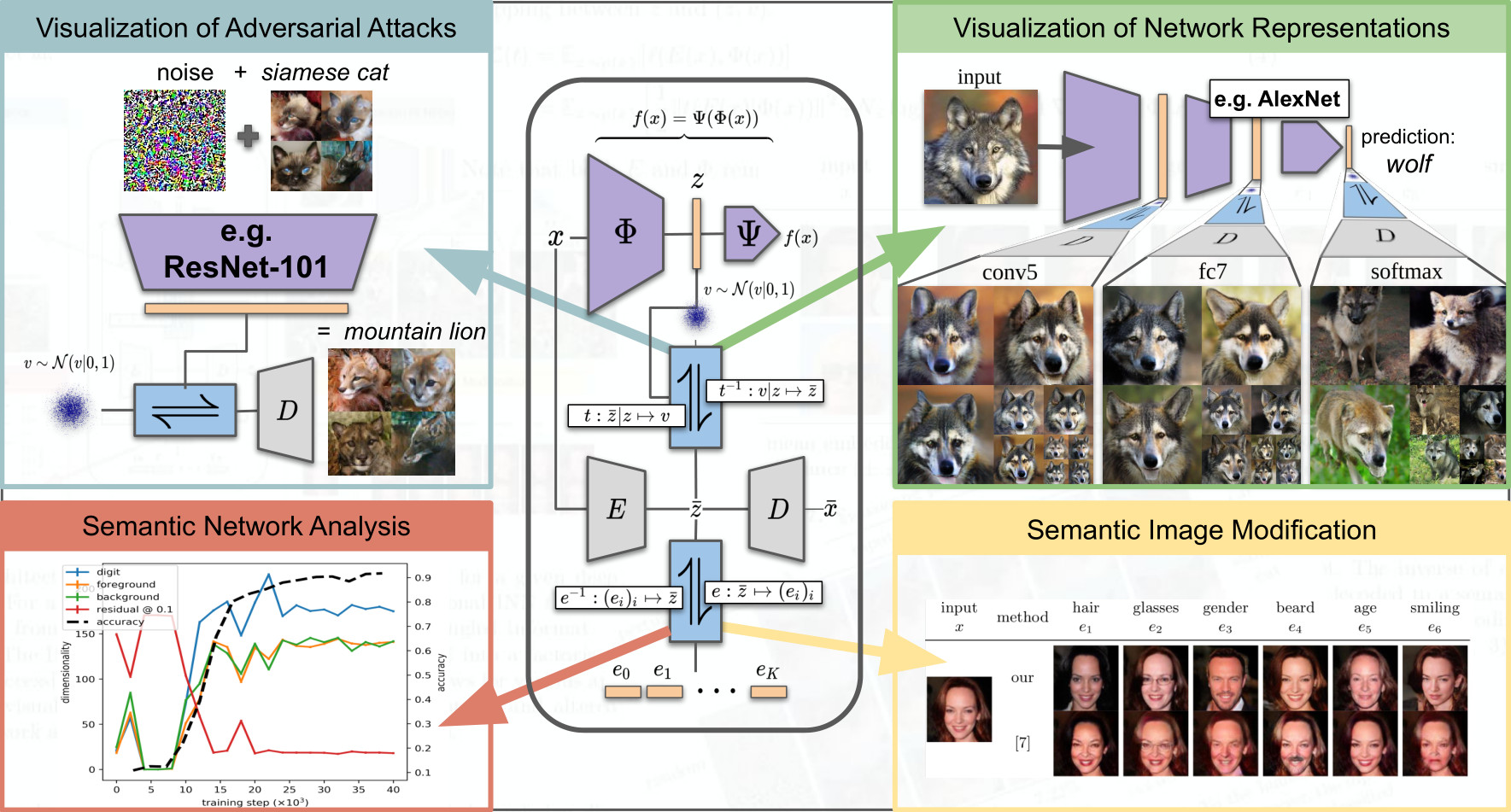
To tackle increasingly complex tasks, it has become an essential ability of neural networks to learn abstract representations. These task-specific representations and, particularly, the invariances they capture turn neural networks into black box models that lack interpretability. To open such a black box, it is, therefore, crucial to uncover the different semantic concepts a model has learned as well as those that it has learned to be invariant to. We present an approach based on INNs that (i) recovers the task-specific, learned invariances by disentangling the remaining factor of variation in the data and that (ii) invertibly transforms these recovered invariances combined with the model representation into an equally expressive one with accessible semantic concepts. As a consequence, neural network representations become understandable by providing the means to (i) expose their semantic meaning, (ii) semantically modify a representation, and (iii) visualize individual learned semantic concepts and invariances. Our invertible approach significantly extends the abilities to understand black box models by enabling post-hoc interpretations of state-of-the-art networks without compromising their performance.
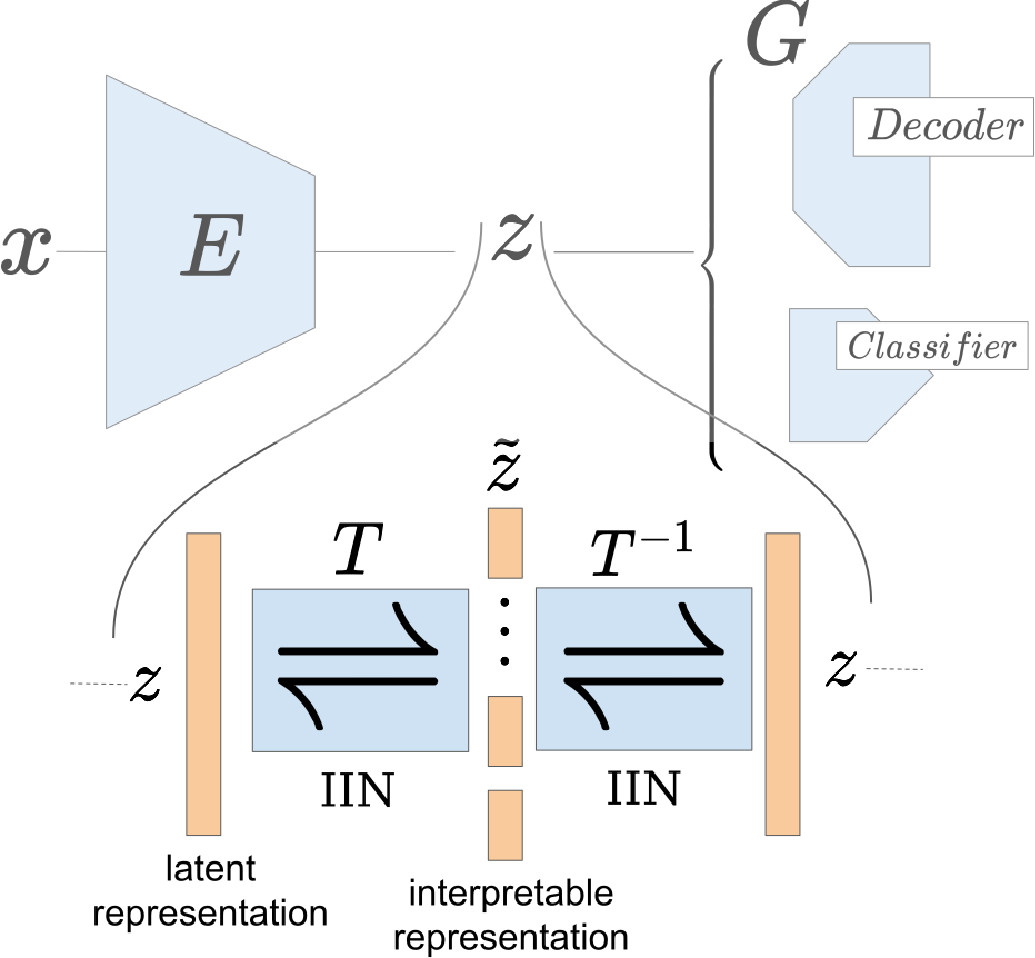
Neural networks have greatly boosted performance in computer vision by learning powerful representations of input data. The drawback of end-to-end training for maximal overall performance are black-box models whose hidden representations are lacking interpretability: Since distributed coding is optimal for latent layers to improve their robustness, attributing meaning to parts of a hidden feature vector or to individual neurons is hindered. We formulate interpretation as a translation of hidden representations onto semantic concepts that are comprehensible to the user. The mapping between both domains has to be bijective so that semantic modifications in the target domain correctly alter the original representation. The proposed invertible interpretation network can be transparently applied on top of existing architectures with no need to modify or retrain them. Consequently, we translate an original representation to an equivalent yet interpretable one and backwards without affecting the expressiveness and performance of the original. The invertible interpretation network disentangles the hidden representation into separate, semantically meaningful concepts. Moreover, we present an efficient approach to define semantic concepts by only sketching two images and also an unsupervised strategy. Experimental evaluation demonstrates the wide applicability to interpretation of existing classification and image generation networks as well as to semantically guided image manipulation.
Results
and applications of our model.
 Figure 1: BERT [15] to BigGAN [4] transfer: Our approach enables translation between fixed off-the-shelve expert models such as BERT and BigGAN without having to modify or finetune them.
Figure 1: BERT [15] to BigGAN [4] transfer: Our approach enables translation between fixed off-the-shelve expert models such as BERT and BigGAN without having to modify or finetune them.
 Figure 2: Proposed architecture. We provide post-hoc model fusion for two given deep networks f = Φ ◦Ψ and g = Θ ◦ Λ which live on arbitrary domains Dx and Dy . For deep representations zΦ = Φ(x) and zΘ = Θ(y), a conditional INN τ learns to transfer between them by modelling the ambiguities w.r.t. the translation as an explicit residual, enabling transfer between given off-the-shelf models and their respective domains.
Figure 2: Proposed architecture. We provide post-hoc model fusion for two given deep networks f = Φ ◦Ψ and g = Θ ◦ Λ which live on arbitrary domains Dx and Dy . For deep representations zΦ = Φ(x) and zΘ = Θ(y), a conditional INN τ learns to transfer between them by modelling the ambiguities w.r.t. the translation as an explicit residual, enabling transfer between given off-the-shelf models and their respective domains.
 Figure 3: Different Image-to-Image translation tasks solved with a single AE g and different experts f .
Figure 3: Different Image-to-Image translation tasks solved with a single AE g and different experts f .
 Figure 4: Superresolution with Network-to-Network Translation. Here, we use our cINN to combine two autoencoders f and g to generatively combine two autoencoders living on image scales 32× 32 and 256× 256.
Figure 4: Superresolution with Network-to-Network Translation. Here, we use our cINN to combine two autoencoders f and g to generatively combine two autoencoders living on image scales 32× 32 and 256× 256.
 Figure 5: Translating different layers of an expert model f to the representation of an autoencoder g reveals the learned invariances of f and thus provides diagnostic insights. Here, f is a segmentation model, while g is the same AE as in Sec. 4.2. For zΦ = Φ(x), obtained from different layers of f , we sample zΘ as in Eq. (7) and synthesize corresponding images Λ(zΘ).
Figure 5: Translating different layers of an expert model f to the representation of an autoencoder g reveals the learned invariances of f and thus provides diagnostic insights. Here, f is a segmentation model, while g is the same AE as in Sec. 4.2. For zΦ = Φ(x), obtained from different layers of f , we sample zΘ as in Eq. (7) and synthesize corresponding images Λ(zΘ).
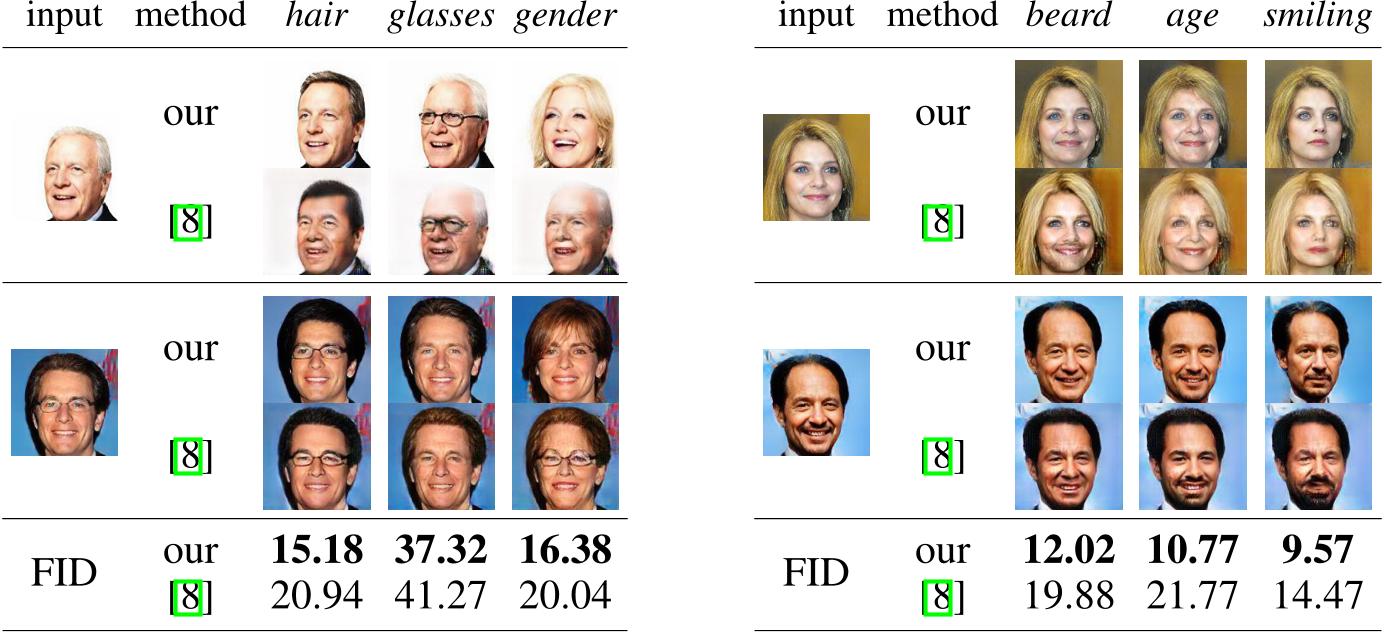 Figure 6: We directly consider attribute vectors for zΦ to perform attribute modifications. We show both qualitative comparisons to [8], obtained by changing a single attribute of the input, as well as quantiative comparisons of FID scores, obtained after flipping a single attribute for all images of the test set. The results demonstrate the value of reusing a powerful, generic autoencoder (AE) g and repurposing it via our approach for a specific task, such as attribute modification, instead of learning an AE and the modification task simultaneously.
Figure 6: We directly consider attribute vectors for zΦ to perform attribute modifications. We show both qualitative comparisons to [8], obtained by changing a single attribute of the input, as well as quantiative comparisons of FID scores, obtained after flipping a single attribute for all images of the test set. The results demonstrate the value of reusing a powerful, generic autoencoder (AE) g and repurposing it via our approach for a specific task, such as attribute modification, instead of learning an AE and the modification task simultaneously.
 Figure 7: In (a), a segmentation representation Φ(x) is translated under the guidance of the residual v = τ−1(Θ(y)|Φ(y)) obtained from exemplar y. In (b), Φ is the same as Θ, but applied after a spatial deformation of its input such that τ learns to extract a shape representation into v, which then controls the target shape.
Figure 7: In (a), a segmentation representation Φ(x) is translated under the guidance of the residual v = τ−1(Θ(y)|Φ(y)) obtained from exemplar y. In (b), Φ is the same as Θ, but applied after a spatial deformation of its input such that τ learns to extract a shape representation into v, which then controls the target shape.
 Figure 8: Unpaired Transfer: Bringing oil portraits and animes to live by projecting them onto the FFHQ dataset (column 1 and 2, respectively). Column 3 visualizes the more subtle differences introduced when translating between different datasets of human faces such as FFHQ and CelebA-HQ. Column 4 shows a translation between the more diverse modalities of human and animal faces. See also Sec. 4.3 and D.
Figure 8: Unpaired Transfer: Bringing oil portraits and animes to live by projecting them onto the FFHQ dataset (column 1 and 2, respectively). Column 3 visualizes the more subtle differences introduced when translating between different datasets of human faces such as FFHQ and CelebA-HQ. Column 4 shows a translation between the more diverse modalities of human and animal faces. See also Sec. 4.3 and D.
 Table 2: Comparison of computational costs for a single training run of different models. Energy consumption of a Titan X is based on the recommended system power (0.6 kW) by NVIDIA5, and energy consumption of eight V100 on the power (3.5 kW) of a NVIDIA DGX-1 system6. Costs are based on the average price of 0.216 EUR per kWh in the EU7, and CO2 emissions on the average emissions of 0.296 kg CO2 per kWh in the EU8.
Table 2: Comparison of computational costs for a single training run of different models. Energy consumption of a Titan X is based on the recommended system power (0.6 kW) by NVIDIA5, and energy consumption of eight V100 on the power (3.5 kW) of a NVIDIA DGX-1 system6. Costs are based on the average price of 0.216 EUR per kWh in the EU7, and CO2 emissions on the average emissions of 0.296 kg CO2 per kWh in the EU8.
 Figure 9: Unsupervised disentangling of shape and appearance. Training our approach on synthetically deformed images, τ learns to extract a disentangled shape representation v from y, which can be recombined with arbitrary appearances obtained from x. See also Sec. C.
Figure 9: Unsupervised disentangling of shape and appearance. Training our approach on synthetically deformed images, τ learns to extract a disentangled shape representation v from y, which can be recombined with arbitrary appearances obtained from x. See also Sec. C.
 Figure 10: Additional examples for unpaired translation between human and animal faces as in Fig. 8. Our approach naturally provides translations in both directions (see Sec. D). Inputs are randomly choosen test examples from either the human or the animal data and translated to the respective other one.
Figure 10: Additional examples for unpaired translation between human and animal faces as in Fig. 8. Our approach naturally provides translations in both directions (see Sec. D). Inputs are randomly choosen test examples from either the human or the animal data and translated to the respective other one.
 Figure 11: Additional examples for unpaired translation of Oil Portraits to FFHQ/CelebA-HQ and Anime to FFHQ/CelebA-HQ. Here, we show samples where the same v is projected onto the respective dataset.
Figure 11: Additional examples for unpaired translation of Oil Portraits to FFHQ/CelebA-HQ and Anime to FFHQ/CelebA-HQ. Here, we show samples where the same v is projected onto the respective dataset.
 Figure 12: Model diagnosis compared to a MLP for the translation. Synthesized samples and FID scores demonstrate that a direct translation with a multilayer perceptron (MLP) does not capture the ambiguities of the translation process and can thus only produce a mean image. In contrast, our cINN correctly captures the variability and produces coherent outputs.
Figure 12: Model diagnosis compared to a MLP for the translation. Synthesized samples and FID scores demonstrate that a direct translation with a multilayer perceptron (MLP) does not capture the ambiguities of the translation process and can thus only produce a mean image. In contrast, our cINN correctly captures the variability and produces coherent outputs.
 Figure 13: Additional examples for exemplar-guided image-to-image translation as in Fig. 7a.
Figure 13: Additional examples for exemplar-guided image-to-image translation as in Fig. 7a.
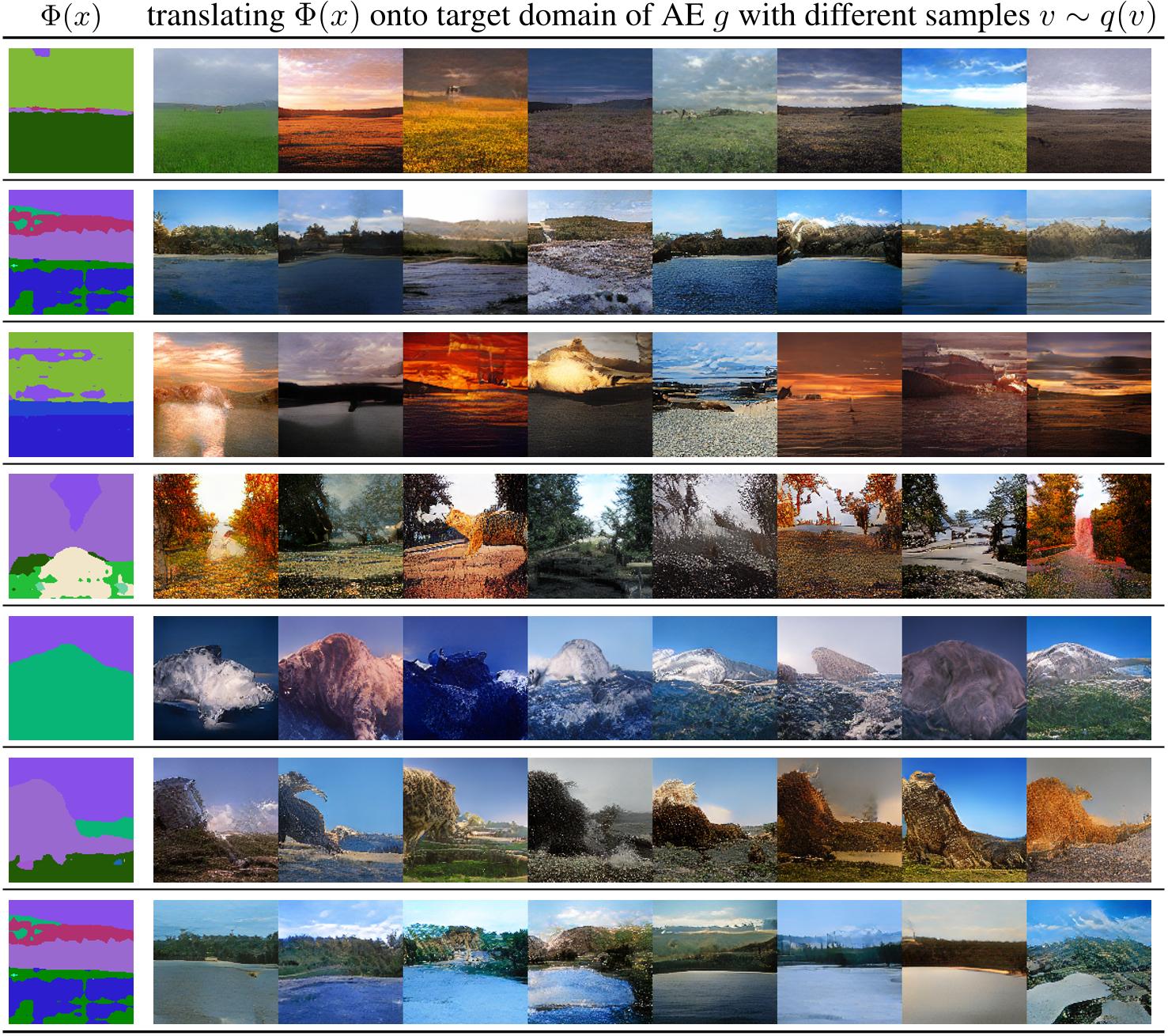 Figure 14: Additional Landscape samples, obtained by translation of the argmaxed logits (i.e. the segmentation output) of the segmentation model from Sec. 4.2, 4.3 into the space of our autoencoder g, see Sec. 4.2, 4.3. The synthesized examples demonstrate that our approach is able to generate diverse and realistic images from a given label map or through a segmentation model.
Figure 14: Additional Landscape samples, obtained by translation of the argmaxed logits (i.e. the segmentation output) of the segmentation model from Sec. 4.2, 4.3 into the space of our autoencoder g, see Sec. 4.2, 4.3. The synthesized examples demonstrate that our approach is able to generate diverse and realistic images from a given label map or through a segmentation model.
 Figure 16: BERT [15] to BigGAN [4] transfer: Additional examples, which demonstrate high diversity in synthesized outputs.
Figure 16: BERT [15] to BigGAN [4] transfer: Additional examples, which demonstrate high diversity in synthesized outputs.
 Slides from our NeurIPS 2020 oral presentation.
Slides from our NeurIPS 2020 oral presentation.
Acknowledgement
This page is based on a design by TEMPLATED. This work has been supported in part by the German Research Foundation (DFG) projects 371923335, 421703927, and EXC 2181/1 - 390900948, the German federal ministry BMWi within the project KI Absicherung and a hardware donation from NVIDIA Corporation.