TL;DR:
We present iPOKE, a model for locally controlled, stochastic video synthesis based on poking a single pixel in a static scene, that enables users to animate still images only with simple mouse drags.
TL;DR:
We present iPOKE, a model for locally controlled, stochastic video synthesis based on poking a single pixel in a static scene, that enables users to animate still images only with simple mouse drags.

Abstract
How would a static scene react to a local poke? What are the effects on other parts of an object if you could locally push it? There will be distinctive movement, despite evident variations caused by the stochastic nature of our world. These outcomes are governed by the characteristic kinematics of objects that dictate their overall motion caused by a local interaction. Conversely, the movement of an object provides crucial information about its underlying distinctive kinematics and the interdependencies between its parts. This two-way relation motivates learning a bijective mapping between object kinematics and plausible future image sequences. Therefore, we propose iPOKE -- invertible Prediction of Object Kinematics -- that, conditioned on an initial frame and a local poke, allows to sample object kinematics and establishes a one-to-one correspondence to the corresponding plausible videos, thereby providing a controlled stochastic video synthesis. In contrast to previous works, we do not generate arbitrary realistic videos, but provide efficient control of movements, while still capturing the stochastic nature of our environment and the diversity of plausible outcomes it entails. Moreover, our approach can transfer kinematics onto novel object instances and is not confined to particular object classes.

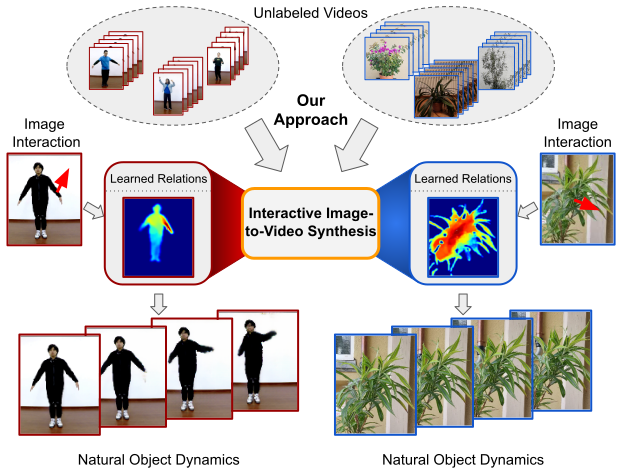
 Understanding object structure: By performing 100 random interactions at the same location \(l\) within a given image frame \(x_0\) we obtain varying video sequences, from which we compute motion correlations for \(l\) with all remaining pixels. By mapping these correlations to the pixel space, we visualize distinct object parts.
Understanding object structure: By performing 100 random interactions at the same location \(l\) within a given image frame \(x_0\) we obtain varying video sequences, from which we compute motion correlations for \(l\) with all remaining pixels. By mapping these correlations to the pixel space, we visualize distinct object parts.