TL;DR: Our approach for interactive image-to-video synthesis learns to understand the relations between the distinct body parts of articulated objects from unlabeled video data, thus enabling synthesis of videos showing natural object dynamics as responses to local interactions.
What would be the effect of locally poking a static scene? We present an approach that learns naturally-looking global articulations caused by a local manipulation at a pixel level. Training requires only videos of moving objects but no information of the underlying manipulation of the physical scene. Our generative model learns to infer natural object dynamics as a response to user interaction and learns about the interrelations between different object body regions. Given a static image of an object and a local poking of a pixel, the approach then predicts how the object would deform over time. In contrast to existing work on video prediction, we do not synthesize arbitrary realistic videos but enable local interactive control of the deformation. Our model is not restricted to particular object categories and can transfer dynamics onto novel unseen object instances. Extensive experiments on diverse objects demonstrate the effectiveness of our approach compared to common video prediction frameworks.
Video Presentation
Approach
A Hierarchical Model for Object Dynamics
Left: Our framework for interactive image-to-video synthesis during training. Right: Our proposed hierarchical latent model \(\boldsymbol{\mathcal{F}}\) for synthesizing dynamics, consisting of a hierarchy of individual RNNs \(\mathcal{F}_n\), each of which operates on a different spatial feature level of the UNet defined by the pretrained encoder \(\mathcal{E}_\sigma\) and the decoder \(\mathcal{G}\). Given the initial object state \(\boldsymbol{\sigma}_0 = [\mathcal{E}_\sigma(x_0)^1,...,\mathcal{E}_\sigma(x_0)^N]\), \(\boldsymbol{\mathcal{F}}\) predicts the next state \(\boldsymbol{\hat{\sigma}}_{i+1} = [\hat{\sigma}_{i+1}^1,...,\hat{\sigma}_{i+1}^N]\) based on its current state \(\hat{\sigma}_i\) and the latent interaction \(\phi_i = \mathcal{E}_\phi(p,l)\) at the corresponding time step. The decoder \(\mathcal{G}\) finally visualizes each predicted object state \(\hat{\sigma}_i\) in an image frame \(\hat{x}_i\).
Results
for the object categories of plants and humans.
When trained on interactions consisting of a shift \(p \in \mathbb{R}^2\) of the pixel at location \(l \in \mathbb{N}^2\), human users can apply our model to synthesize plausible object resppnses
to such interactions based on still images. That is, human users can define the intended target location for the poked object part while our model infers matching object dynamics
for the remainder of object parts.
Plants
As our model does not make assumptions about the objects to interact with and, thus, can be flexibly learned from unlabeled videos, it is capable to
generate realistic looking video sequences of the distinct types of plants contained in our self-recorded PokingPlants dataset, despite their drastically varying shapes.
Results on the PP datasets for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the PP datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the PP datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the PP datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Humans
Also dynamics of highly-articulated objects such as humans can be learned without annotations available. Moreover, our model generalizes to unseen new instances, which have not been seen during training.
Results on the iPER datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the iPER datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the iPER datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Results on the iPER datasets, for simulated pokes obtained from optical flow in the test set and also for very distinct pokes from human users.
Understanding Object Structure
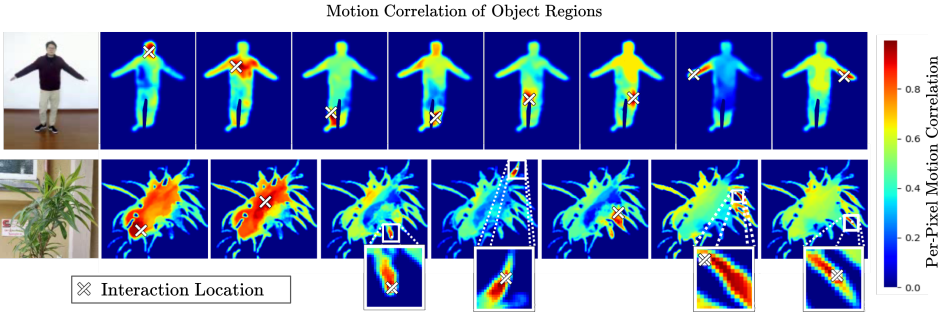
Understanding object structure: By performing 100 random interactions at the same location \(l\) within a given image frame \(x_0\) we obtain varying video sequences, from which we compute motion correlations for \(l\) with all remaining pixels. By mapping these correlations to the pixel space, we visualize distinct object parts.
Additional Results for Human Dynamics
Our hierarchical model can also be applied to in-the-wild settings, as visualized by its generated sequences on the Tai-Chi dataset or to generate complex human motion such as walking sequences on the Human3.6M dataset.
Results of our model on the Tai-Chi dataset which contains many in-the-wild scenes as well as substantial amounts of background camera movements,
thus proving our model to also be able to handle such challenging conditions.
Results of our model on the Tai-Chi dataset which contains many in-the-wild scenes as well as substantial amounts of background camera movements,
thus proving our model to also be able to handle such challenging conditions.
Results of our model on the Tai-Chi dataset which contains many in-the-wild scenes as well as substantial amounts of background camera movements,
thus proving our model to also be able to handle such challenging conditions.
Results on the Tai-Chi dataset which contains many in-the-wild scenes as well as substantial amounts of background camera movements, thus proving our model to also be able to handle such challenging conditions.
Results on the Human3.6M dataset, which contains complex human motion such as walking.
Results on the Human3.6M dataset, which contains complex human motion such as walking.
Additional Applications and Experiments
Interpreting the poke as initial impulse
When normalizing the magnitude of pokes over the entire dataset to be in between 0 and 1, thus removing information regarding the intended target location, the poke can be interpreted as an initial force pr impulse onto
the object part interacted with. Consequently, our model now generates sequences showing object reactions to the initial impulse defined by the interaction, where larger pokes correspond
to similarly large amounts of object dynamics whereas interactions with a small magnitude result in subtle object motion.
Results for the interpretation of poke as an initial impulse onto the object at the respective location.
Results for the interpretation of poke as an initial impulse onto the object at the respective location.
Generalization to Images obtained from web-search
When combining the PP dataset and the vegetation samples from the Dynamic Textures Database, our model can be shown to generalize to images obtained from web-search.
Results on images obtained from web-search demonstrate the generalization capabilities of our model. In last column, we show the nearest neighbour of the respective input image in the train data.
Results on images obtained from web-search demonstrate the generalization capabilities of our model. In last column, we show the nearest neighbour of the respective input image in the train data.
Results on images obtained from web-search demonstrate the generalization capabilities of our model. In last column, we show the nearest neighbour of the respective input image in the train data.
Results on images obtained from web-search demonstrate the generalization capabilities of our model. In last column, we show the nearest neighbour of the respective input image in the train data.
Acknowledgement
The research leading to these results is funded by the German Federal Ministry for Economic Affairs and Energy within the project “KI-Absicherung – Safe AI for automated driving” and by the German Research Foundation (DFG) within project 421703927.
This page is based on a design by TEMPLATED.
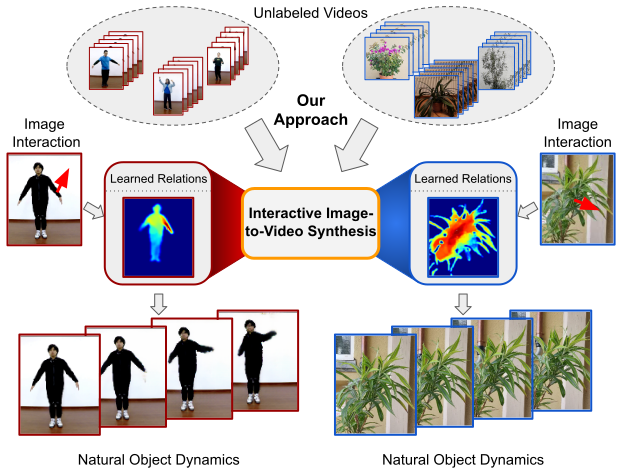 TL;DR: Our approach for interactive image-to-video synthesis learns to understand the relations between the distinct body parts of articulated objects from unlabeled video data, thus enabling synthesis of videos showing natural object dynamics as responses to local interactions.
TL;DR: Our approach for interactive image-to-video synthesis learns to understand the relations between the distinct body parts of articulated objects from unlabeled video data, thus enabling synthesis of videos showing natural object dynamics as responses to local interactions.

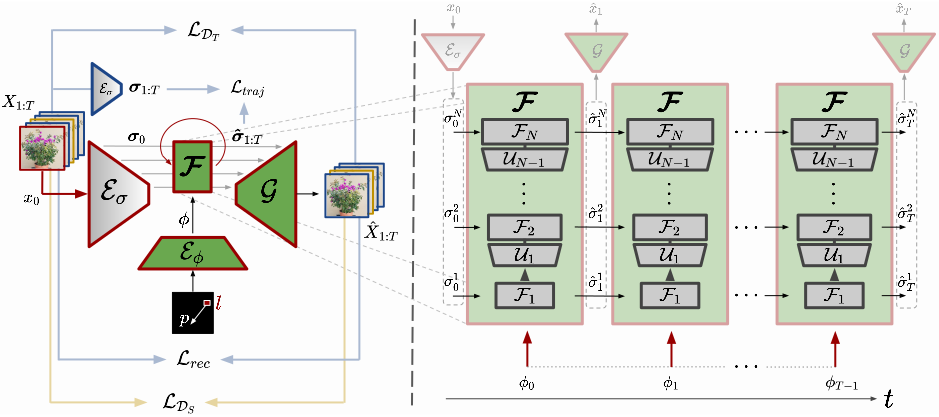 Left: Our framework for interactive image-to-video synthesis during training. Right: Our proposed hierarchical latent model \(\boldsymbol{\mathcal{F}}\) for synthesizing dynamics, consisting of a hierarchy of individual RNNs \(\mathcal{F}_n\), each of which operates on a different spatial feature level of the UNet defined by the pretrained encoder \(\mathcal{E}_\sigma\) and the decoder \(\mathcal{G}\). Given the initial object state \(\boldsymbol{\sigma}_0 = [\mathcal{E}_\sigma(x_0)^1,...,\mathcal{E}_\sigma(x_0)^N]\), \(\boldsymbol{\mathcal{F}}\) predicts the next state \(\boldsymbol{\hat{\sigma}}_{i+1} = [\hat{\sigma}_{i+1}^1,...,\hat{\sigma}_{i+1}^N]\) based on its current state \(\hat{\sigma}_i\) and the latent interaction \(\phi_i = \mathcal{E}_\phi(p,l)\) at the corresponding time step. The decoder \(\mathcal{G}\) finally visualizes each predicted object state \(\hat{\sigma}_i\) in an image frame \(\hat{x}_i\).
Left: Our framework for interactive image-to-video synthesis during training. Right: Our proposed hierarchical latent model \(\boldsymbol{\mathcal{F}}\) for synthesizing dynamics, consisting of a hierarchy of individual RNNs \(\mathcal{F}_n\), each of which operates on a different spatial feature level of the UNet defined by the pretrained encoder \(\mathcal{E}_\sigma\) and the decoder \(\mathcal{G}\). Given the initial object state \(\boldsymbol{\sigma}_0 = [\mathcal{E}_\sigma(x_0)^1,...,\mathcal{E}_\sigma(x_0)^N]\), \(\boldsymbol{\mathcal{F}}\) predicts the next state \(\boldsymbol{\hat{\sigma}}_{i+1} = [\hat{\sigma}_{i+1}^1,...,\hat{\sigma}_{i+1}^N]\) based on its current state \(\hat{\sigma}_i\) and the latent interaction \(\phi_i = \mathcal{E}_\phi(p,l)\) at the corresponding time step. The decoder \(\mathcal{G}\) finally visualizes each predicted object state \(\hat{\sigma}_i\) in an image frame \(\hat{x}_i\).