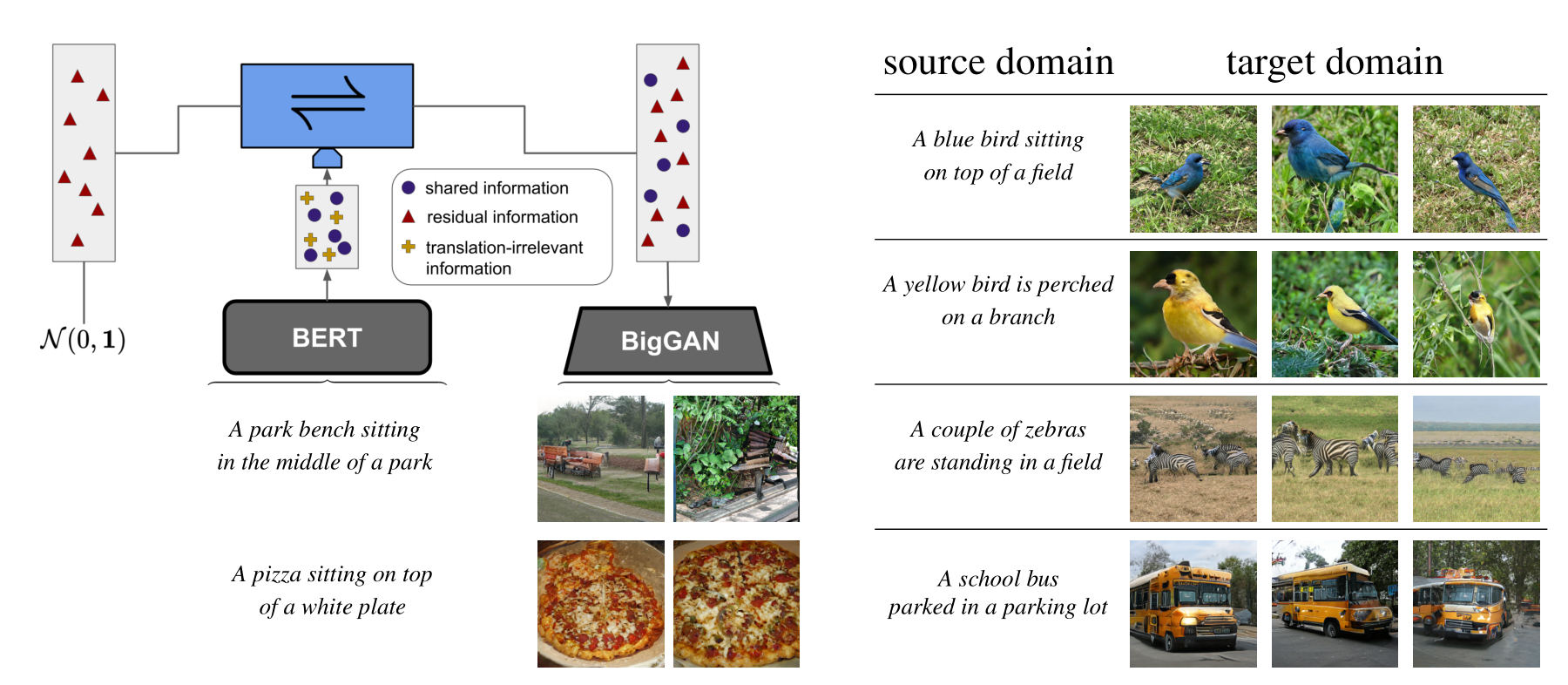
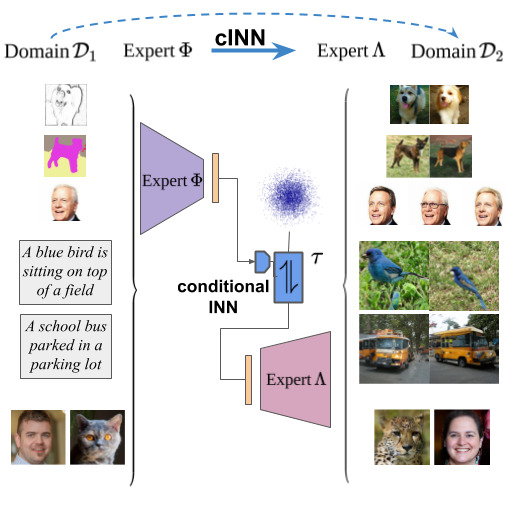
 We learn a conditional invertible neural network (cINN) to
translate between representations of different domain
experts. This results in a fused model, which can be
controlled through the first expert to create novel and
diverse content in the domain of the second expert.
We learn a conditional invertible neural network (cINN) to
translate between representations of different domain
experts. This results in a fused model, which can be
controlled through the first expert to create novel and
diverse content in the domain of the second expert.

Abstract
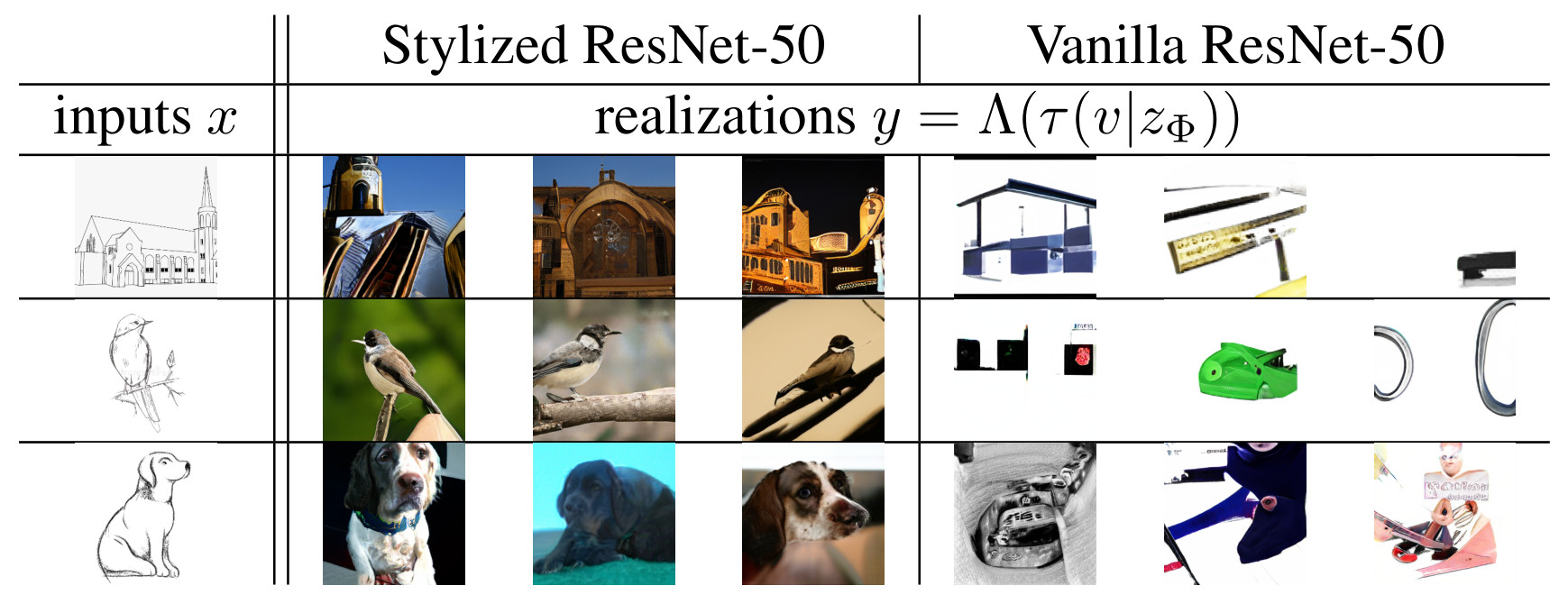
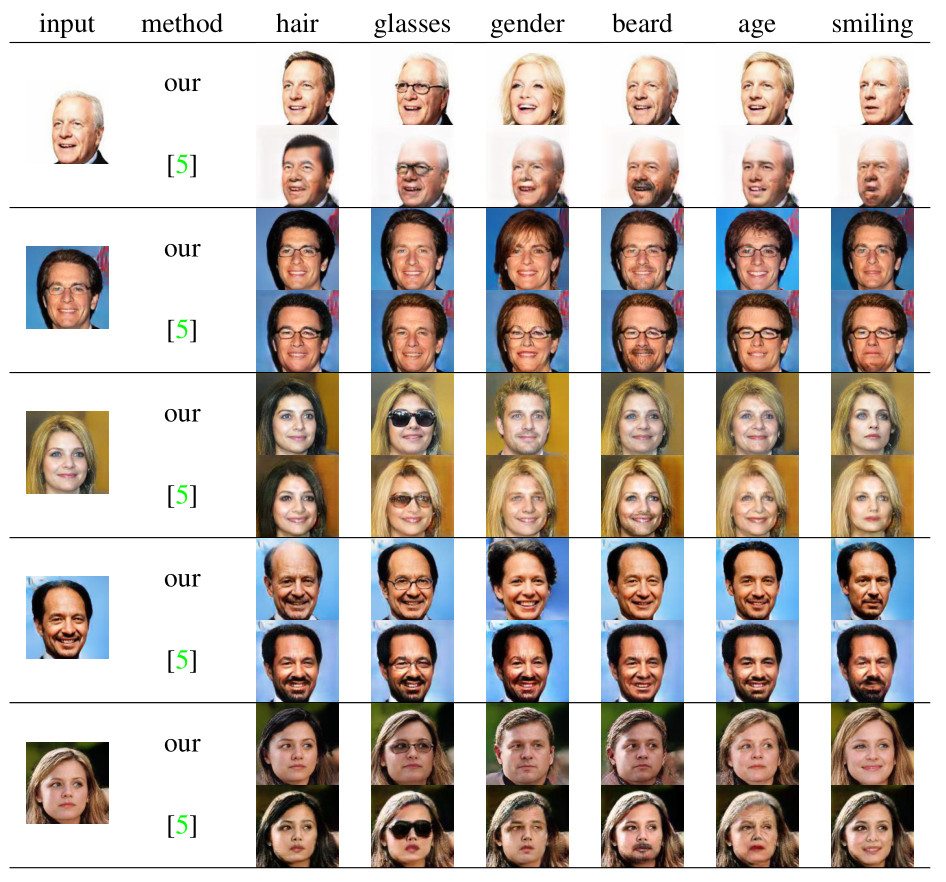
Artificial Intelligence for Content Creation has the potential to reduce the amount of manual content creation work significantly. While automation of laborious work is welcome, it is only useful if it allows users to control aspects of the creative process when desired. Furthermore, widespread adoption of semi-automatic content creation depends on low barriers regarding the expertise, computational budget and time required to obtain results and experiment with new techniques. With state-of-the-art approaches relying on task-specific models, multi-GPU setups and weeks of training time, we must find ways to reuse and recombine them to meet these requirements. Instead of designing and training methods for controllable content creation from scratch, we thus present a method to repurpose powerful, existing models for new tasks, even though they have never been designed for them. We formulate this problem as a translation between expert models, which includes common content creation scenarios, such as text-to-image and image-to-image translation, as a special case. As this translation is ambiguous, we learn a generative model of hidden representations of one expert conditioned on hidden representations of the other expert. Working on the level of hidden representations makes optimal use of the computational effort that went into the training of the expert model to produce these efficient, low-dimensional representations. Experiments demonstrate that our approach can translate from BERT, a state-of-the-art expert for text, to BigGAN, a state-of-the-art expert for images, to enable text-to-image generation, which neither of the experts can perform on its own. Additional experiments show the wide applicability of our approach across different conditional image synthesis tasks and improvements over existing methods for image modifications.
Our architecture builds upon our prior
work
"A Disentangling
Invertible Interpretation Network for Explaining Latent
Representations"