
TL;DR
- Generative Decoding. Generative rectified-flow encoder–decoder for nowcasting with uncertainty-aware compression.
- FREUD Architecture. Frame-wise encoder + unified decoder enables variable-length inputs, robustness to frame drops, and preserves temporal consistency.
- Simple Training. No loss weight tuning, trained with a simple, stable flow-matching objective.
- SOTA Nowcasting. Rectified-flow model in FREUD latent space achieves state-of-the-art distributional and perceptual forecasting quality.
Abstract
Accurate weather forecasts are essential across various domains and are safety-critical in extreme weather conditions. Compared to simulation-based forecasting, data-driven approaches show greater efficiency, enabling short-term, high-resolution nowcasting. In particular, diffusion models proved effective in weather nowcasting due to their strong probabilistic foundation. However, existing methods rely on deterministic compression to reduce the complexity of high-dimensional weather data, limiting their ability to capture uncertainty in the decoding process. In this work, we introduce FREUD, a Frame-wise encoder and United Decoder model based on rectified flow transformers for efficient compression of spatio-temporal weather data. Frame-wise encoding enables continuous forecast updates, while the unified video decoder ensures temporal consistency. Our uncertainty-preserving first stage allows us to capture aleatoric uncertainty through ensembling, which is particularly beneficial for extreme weather events with high decoding variability. We achieve state-of-the-art performance in precipitation nowcasting with a compact latent-space rectified flow transformer on the SEVIR benchmark and show further performance gains by scaling model size. With FREUD and the latent rectified flow model, we aim to push the boundaries of data-driven weather nowcasting.
Method


Our pipeline is built around FREUD, a first-stage model with a frame-wise transformer encoder and a united generative rectified flow decoder. The frame-wise encoder processes each context frame independently, which prevents information leakage from future to past and supports incremental updates when new radar frames arrive. The united decoder then reconstructs all frames jointly, improving temporal consistency and reducing artifacts that appear with purely frame-wise decoding. Because decoding is probabilistic, we can sample multiple reconstructions from the same latent representation and estimate decoding uncertainty through ensemble variance. We regularize the latent space with a novel stochastic tanh regularization, producing bounded and smooth latents without relying on adversarial or perceptual losses. On top of this first stage, we train a latent-space rectified-flow forecasting model with masking-based conditioning, allowing robust inference under variable numbers of observed input frames. During inference, we sample ensemble forecasts in latent space and decode them to pixel space, yielding calibrated, uncertainty-aware precipitation nowcasts.
Key Results
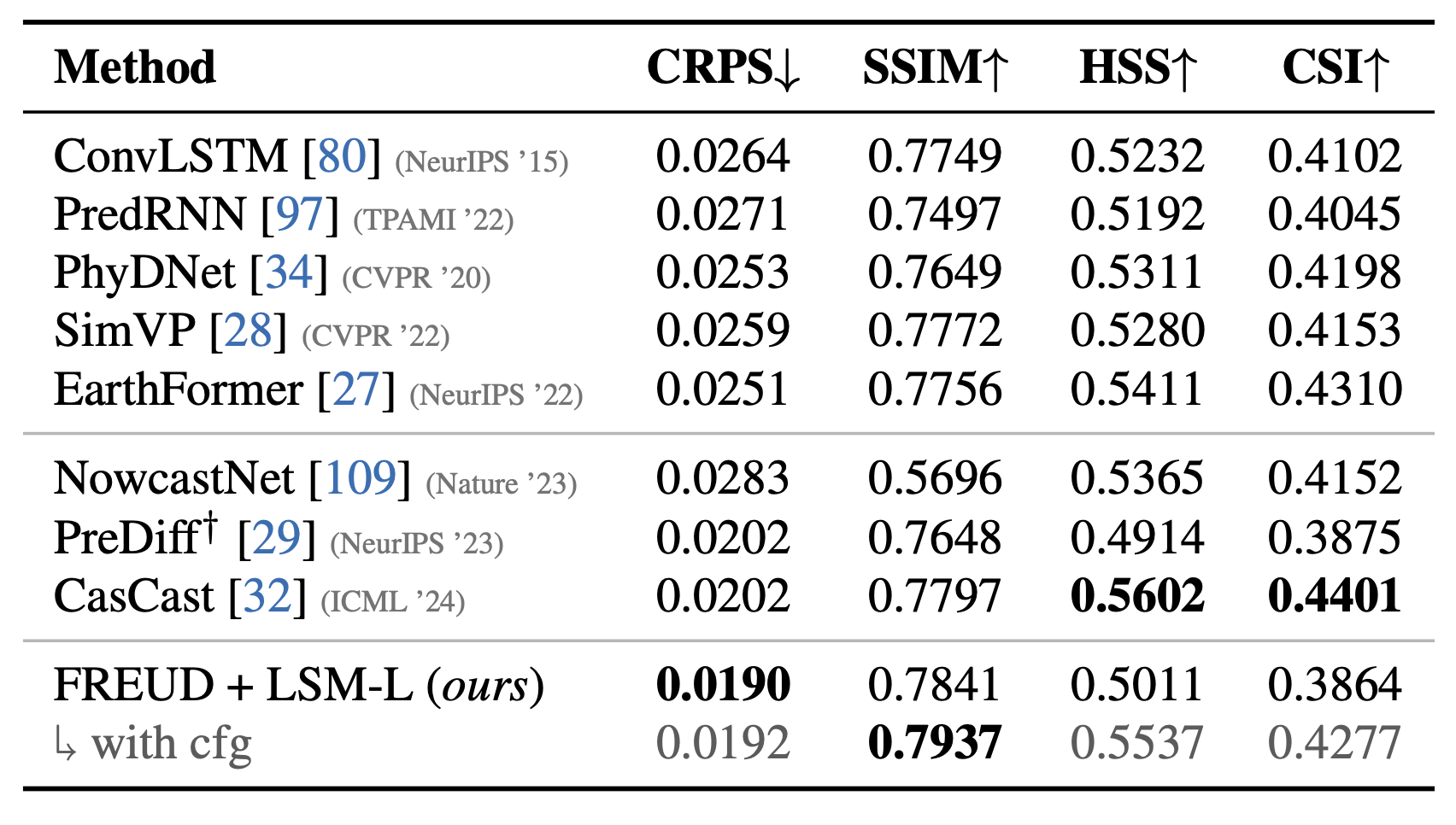
- State-of-the-art forecasting quality on SEVIR: An L-scale ViT (LSM-L) in FREUD latent space reaches state-of-the-art CRPS and SSIM, improving over prior latent diffusion baselines in distributional and perceptual quality, while maintaining competitive localization performance (HSS, CSI).
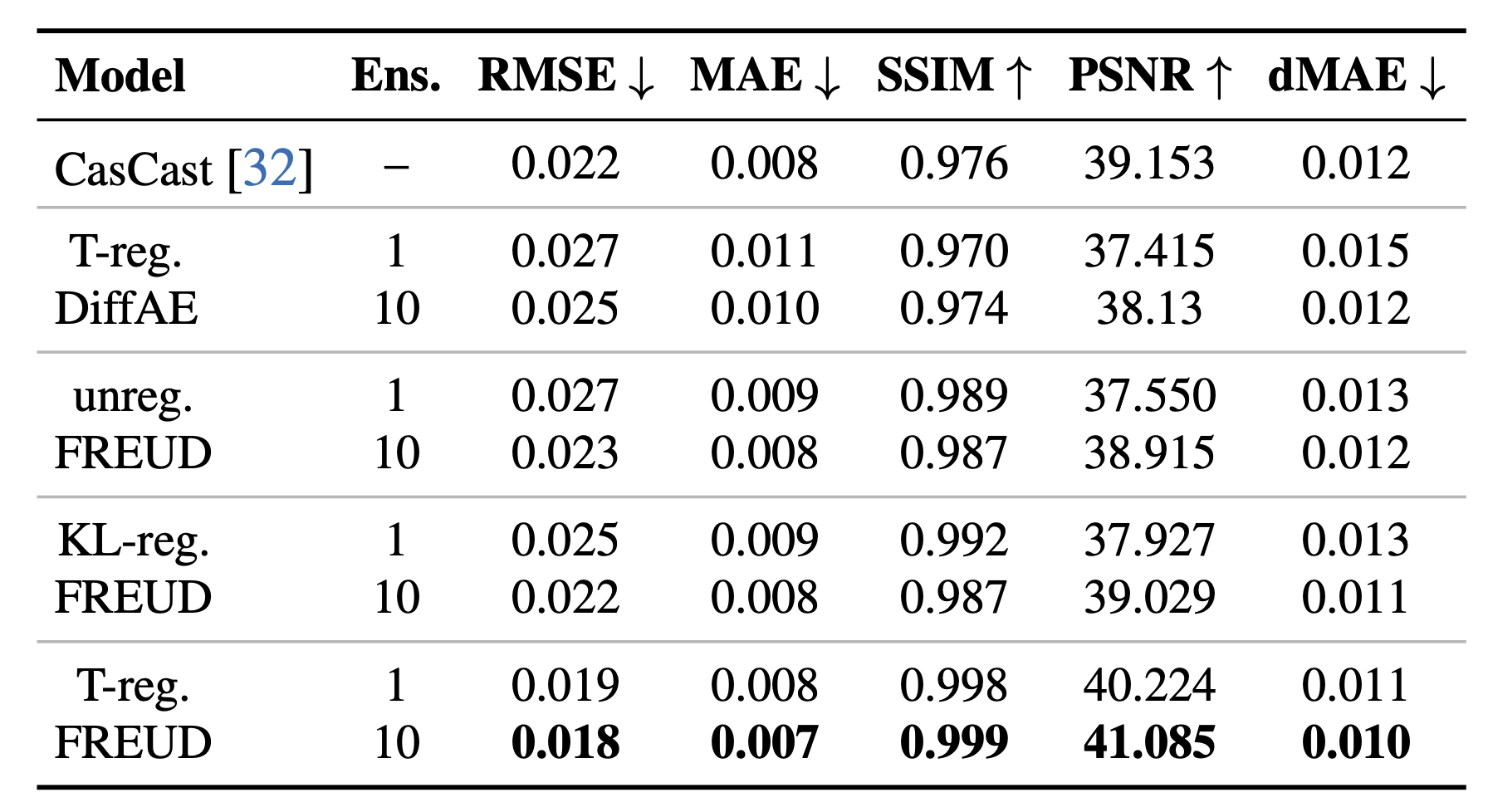
- Improved Reconstruction: FREUD achieves superior reconstruction quality compared to deterministic baselines, which rely on adversarial/perceptual losses as well as KL-regularization.
- Better calibration: Ensemble rank histograms are substantially closer to uniform than CasCast, indicating less overconfident predictions, by avoiding deterministic priors.
- Uncertainty where it matters: Reconstruction ensemble variance increases with precipitation intensity and tracks chaotic extreme-weather regions.
- Efficient and scalable: The first stage is lighter than previous designs and improves when using more compute at inference time.
- Robust operational behavior: Masking-based conditioning supports variable input context and remains effective with limited observations.
Forecasts Comparison
Our forecasts remain realistic and sharp, while CasCast diverges to unrealistic predictions and Earthformer produces increasingly blurry forecasts.
Extreme Weather
Our model is able to capture the chaotic dynamics of extreme weather events such as hurricanes, capturing the complex circular motion of long-tail events.
Citation
@inproceedings{schusterbauer2026weatherrf,
title = {Probabilistic Precipitation Nowcasting with Rectified Flow Transformers},
author = {Schusterbauer, Johannes and Wiese, Jannik and Stracke, Nick and Phan, Timy and Ommer, Bj{\"o}rn},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2026}
}