 * equal contribution
* equal contribution
Abstract
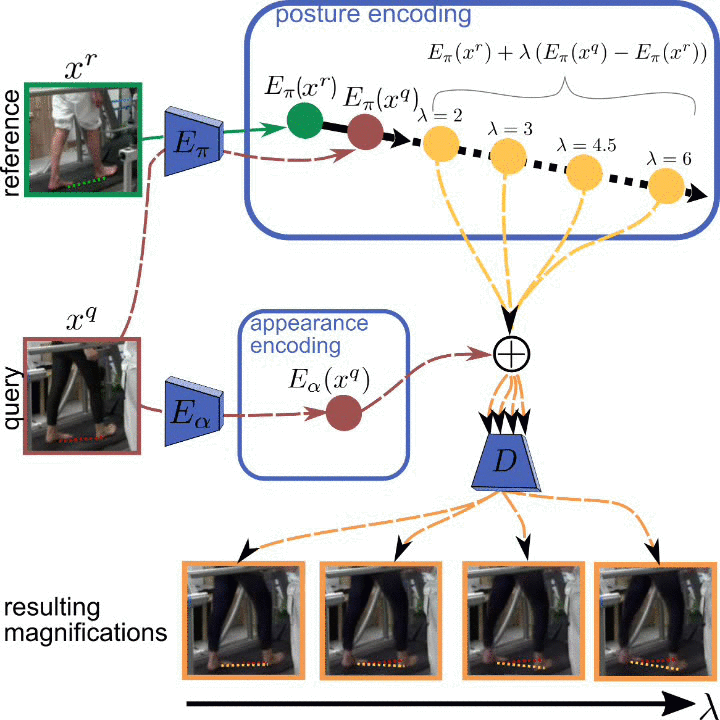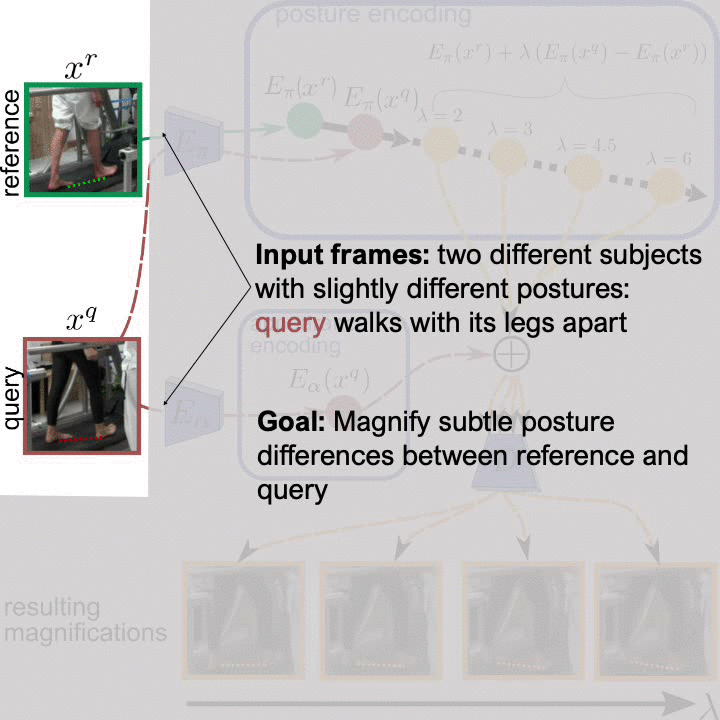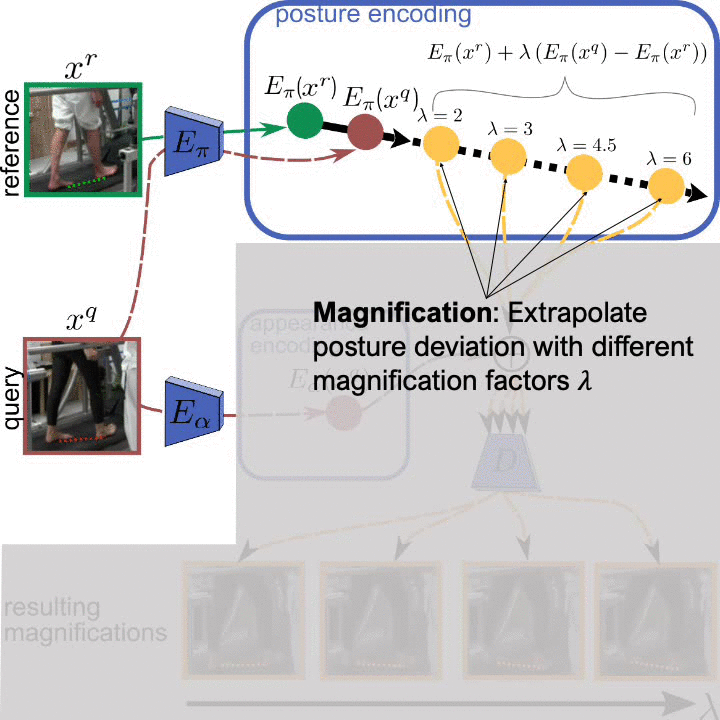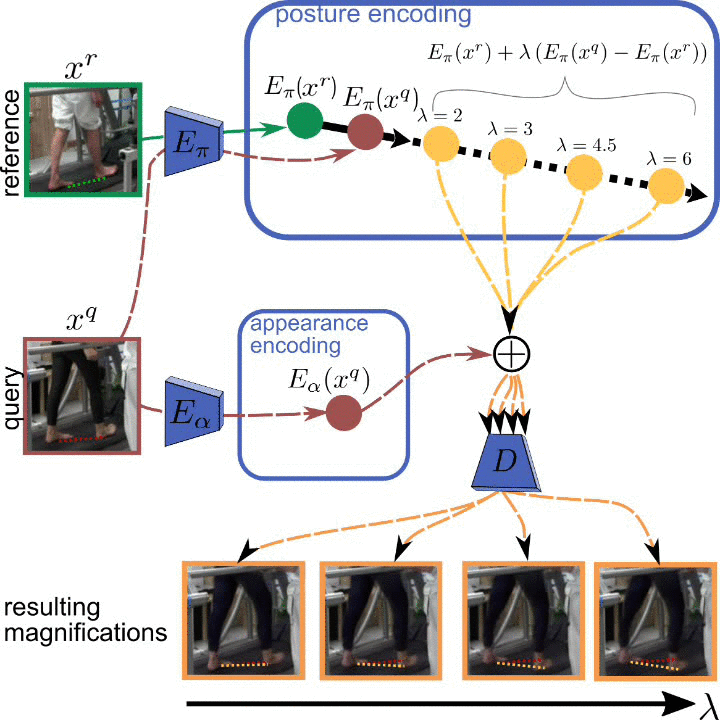
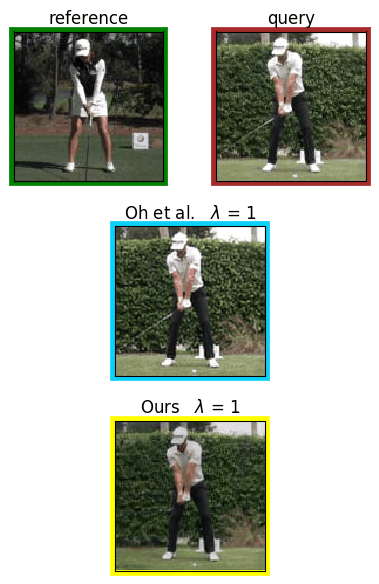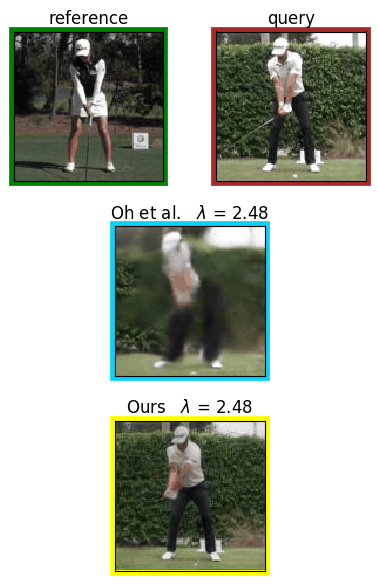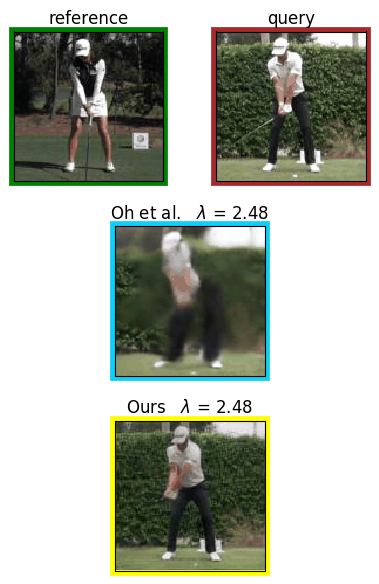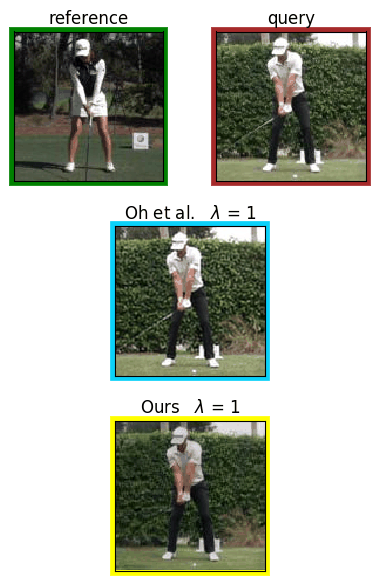
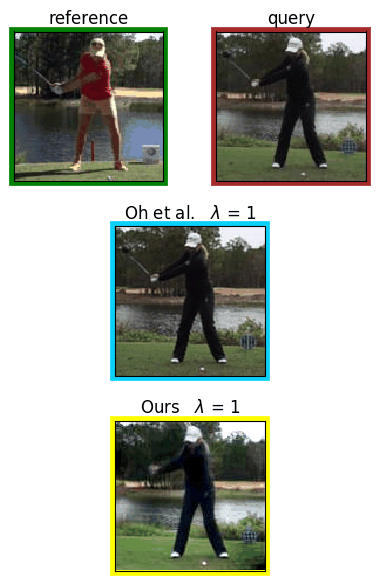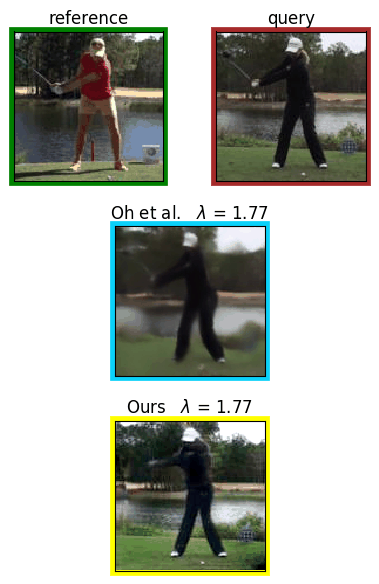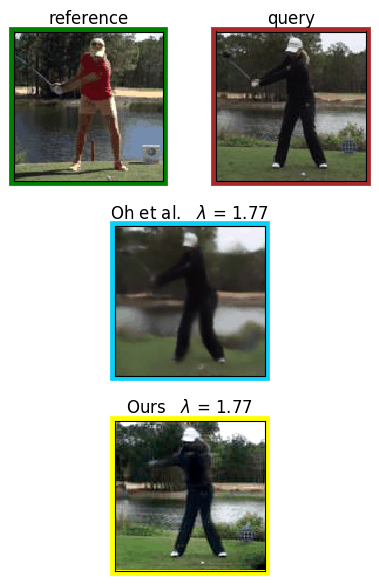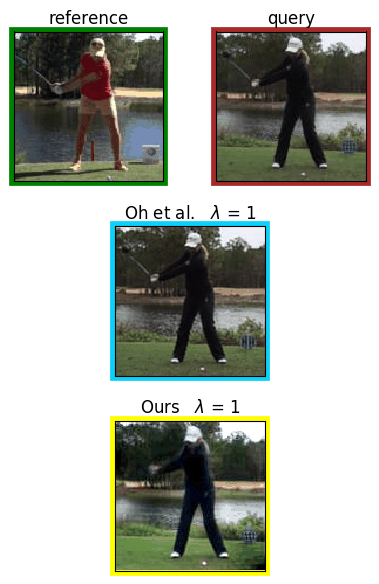
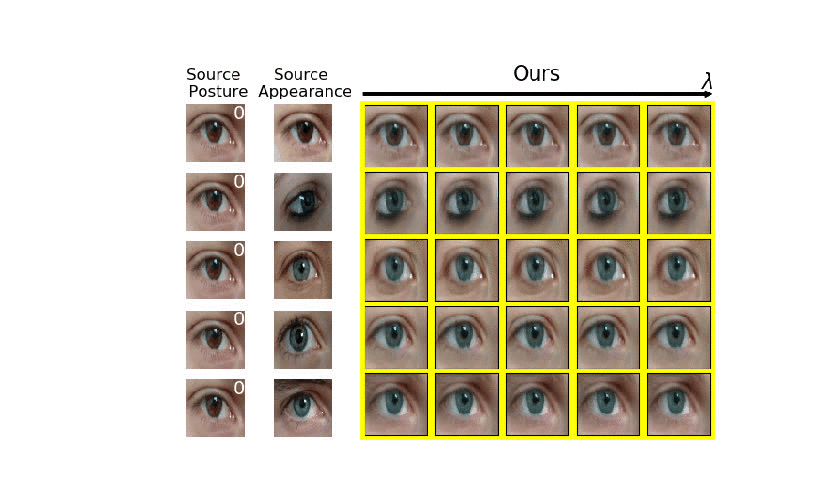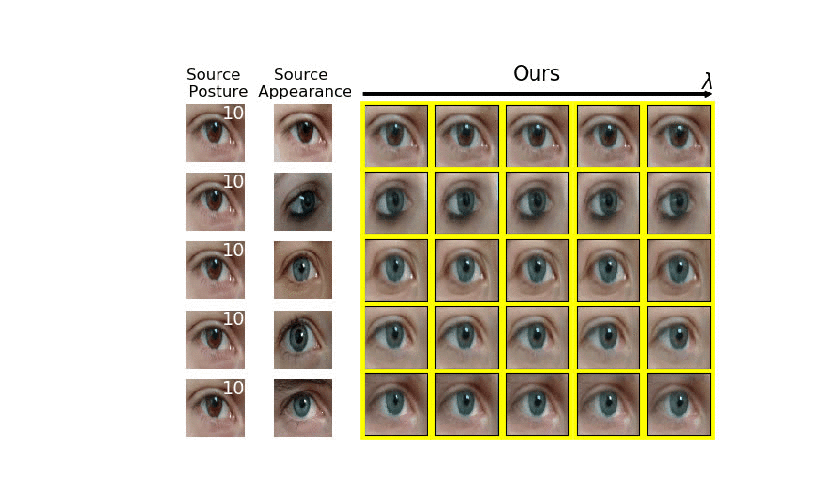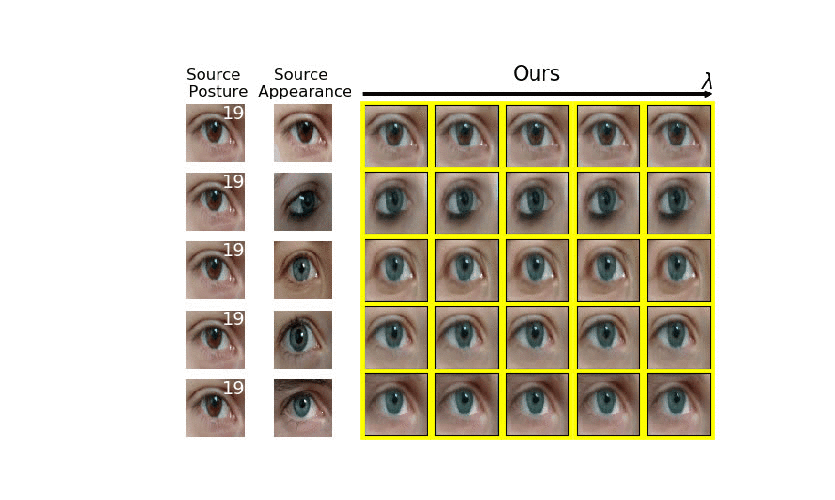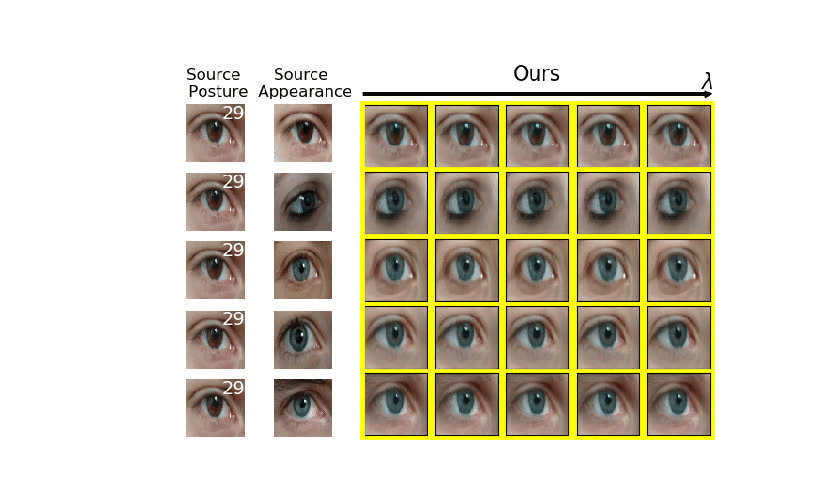
Analyzing human posture and precisely comparing it across different subjects is essential for accurate understanding of behavior and numerous vision applications such as medical diagnostics or sports. Motion magnification techniques help to see even small deviations in posture that are invisible to the naked eye. However, they fail when comparing subtle posture differences across individuals with diverse appearance. Keypoint-based posture estimation and classification techniques can handle large variations in appearance, but are invariant to subtle deviations in posture. We present an approach to unsupervised magnification of posture differences across individuals despite large deviations in appearance. We do not require keypoint annotation and visualize deviations on a sub-bodypart level. To transfer appearance across subjects onto a magnified posture, we propose a novel loss for disentangling appearance and posture in an autoencoder. Posture magnification yields exaggerated images that are different from the training set. Therefore, we incorporate magnification already into the training of the disentangled autoencoder and learn on real data and synthesized magnifications without supervision. Experiments confirm that our approach improves upon the state-of-the-art in magnification and on the application of discovering posture deviations due to impairment.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}