
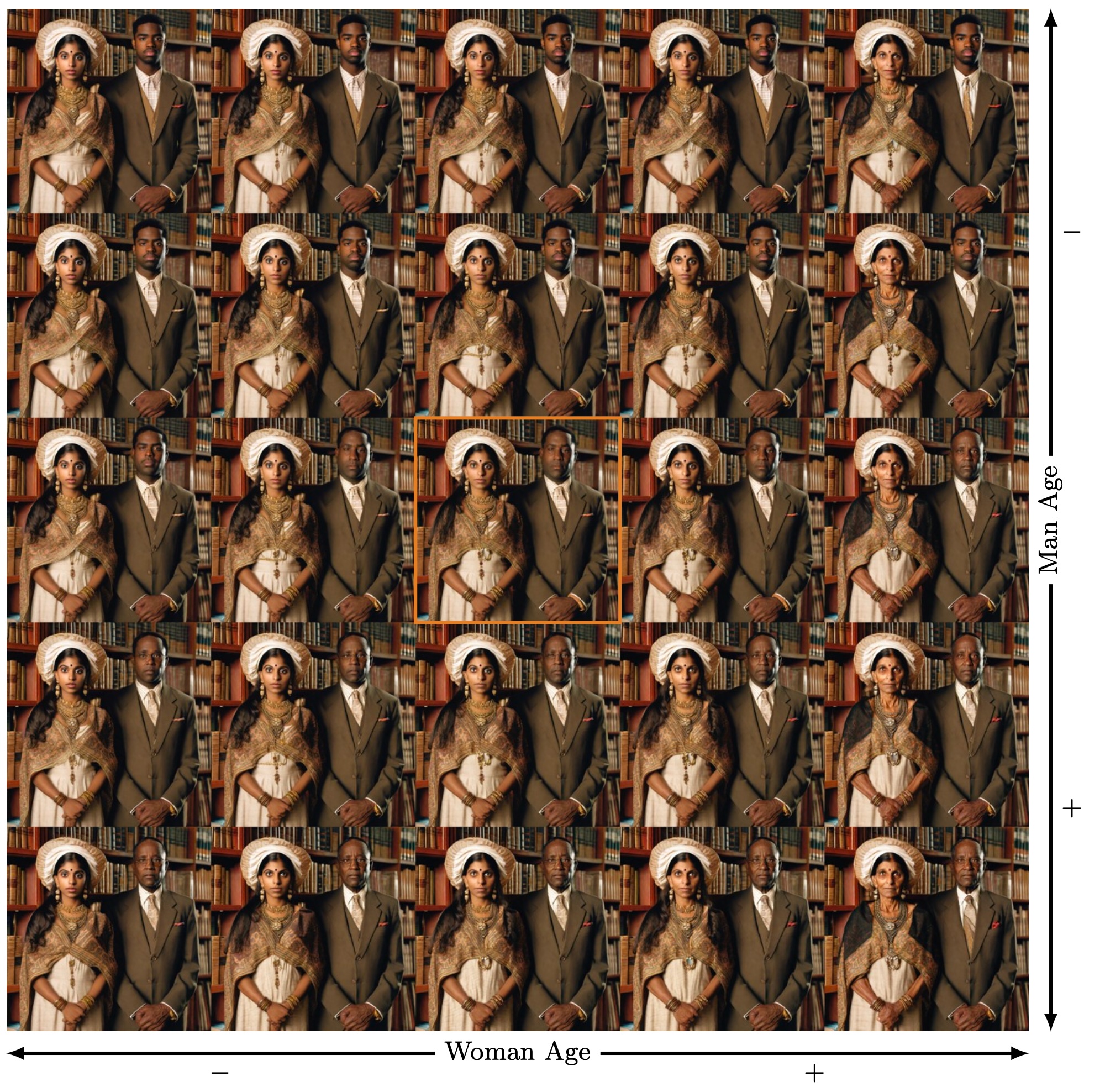
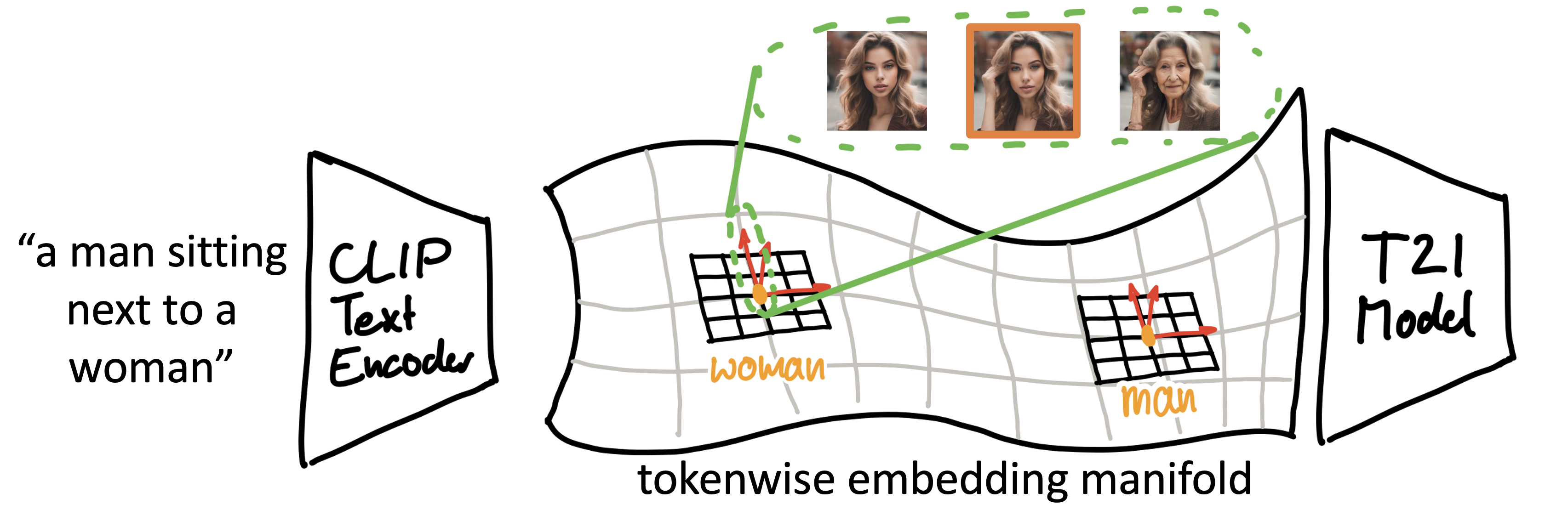
In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model.













@misc{baumann2024attributecontrol,
title={{C}ontinuous, {S}ubject-{S}pecific {A}ttribute {C}ontrol in {T}2{I} {M}odels by {I}dentifying {S}emantic {D}irections},
author={Stefan Andreas Baumann and Felix Krause and Michael Neumayr and Nick Stracke and Vincent Tao Hu and Bj{\"o}rn Ommer},
year={2024},
eprint={2403.17064},
archivePrefix={arXiv},
primaryClass={cs.CV}
}