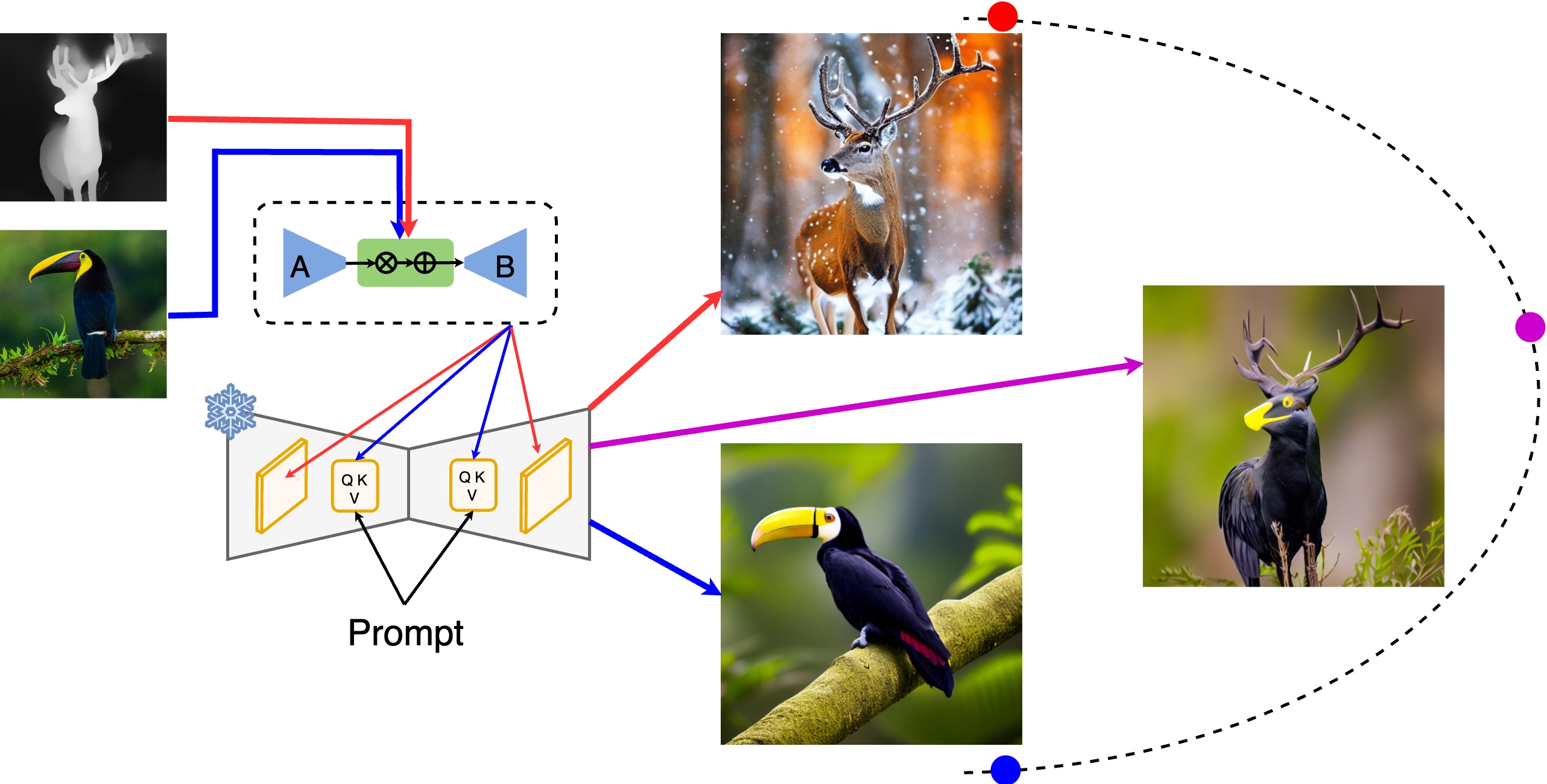
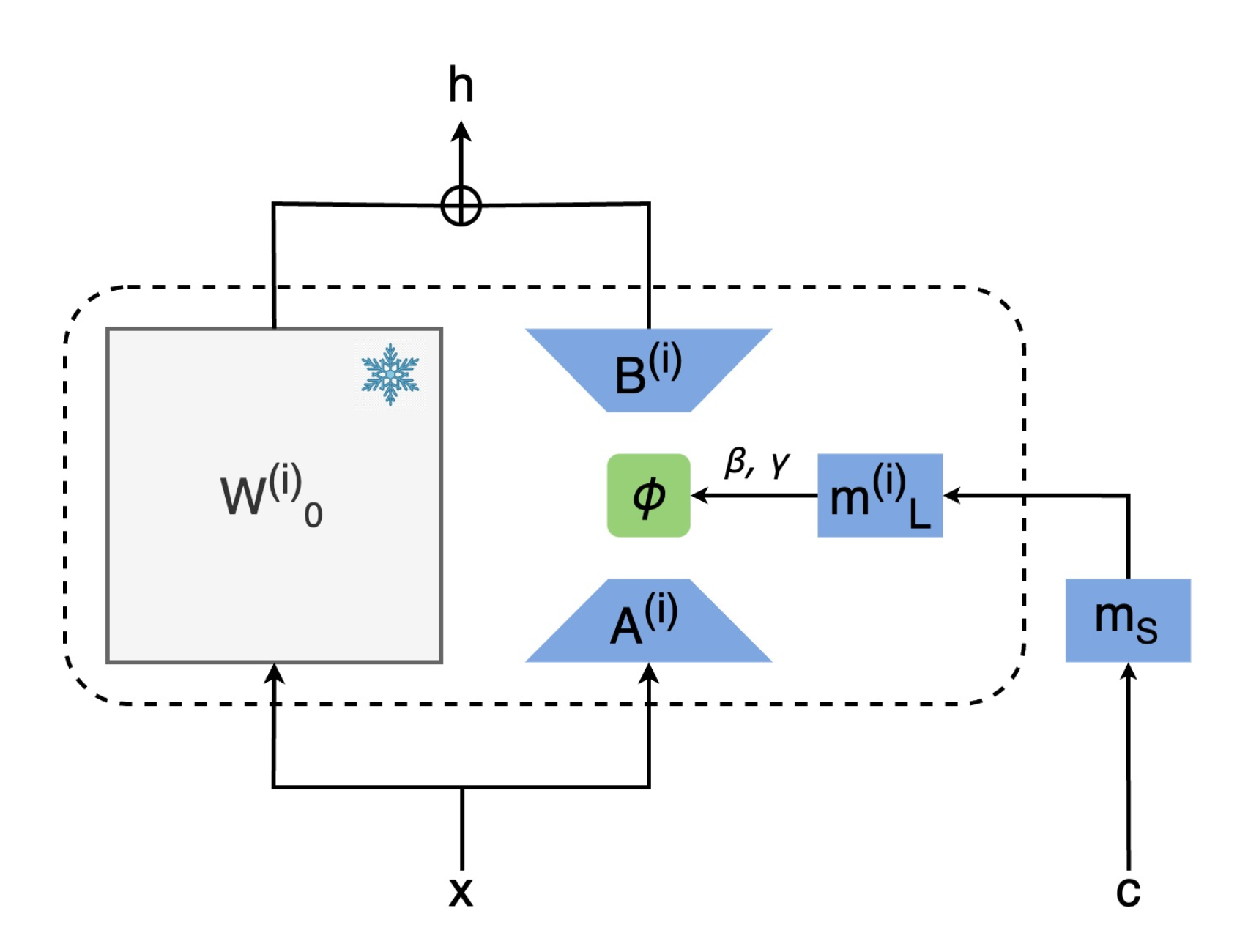
Style

Samples from our method with style conditioning compared against other methods. We used an empty prompt and only conditioned on the image. We generally perform on par with IP-Adapter and outperform it on some samples. Note that the third image from the left is less degraded, and the third image from the right captures the mane of the horse better.
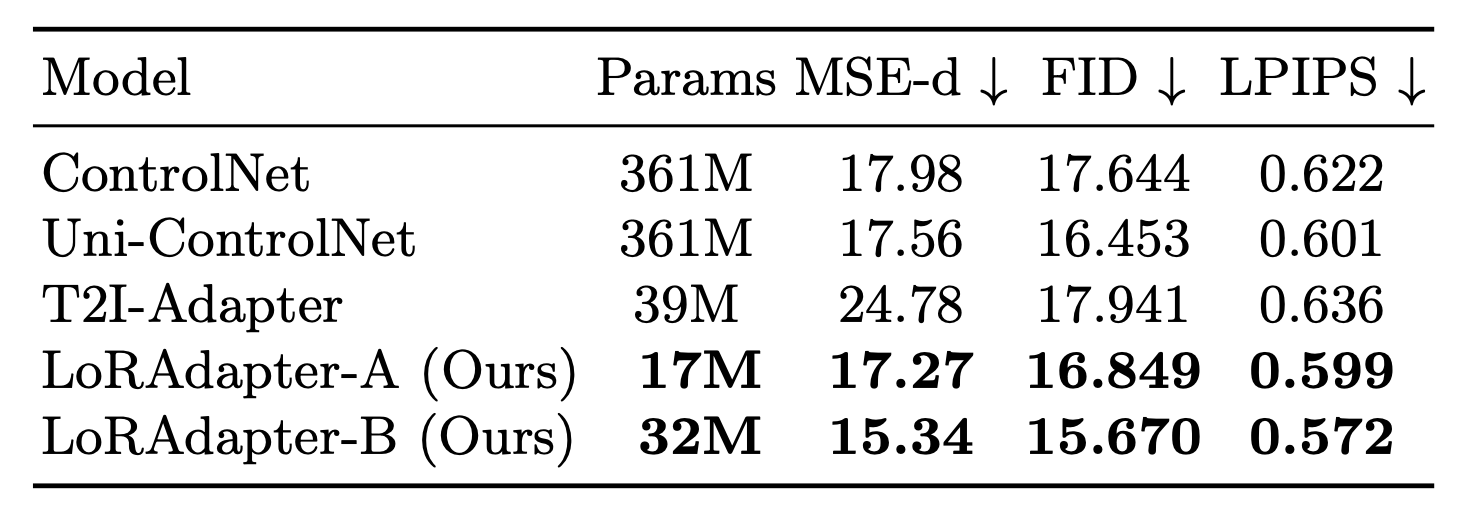
Structure

Samples from our method with structural conditioning compared against other methods. Note that for our method, especially compared with T2I Adapter, the details of the images are substantially more closely aligned with the depth prompt (see e.g. the lamp in the background of the living room scene and the side table's legs, or the salad on the pizza)